Truncate bag to avoid ecological implausibility in the model
Source:R/truncate_bag.R
truncate_bag.RdThis function identifies sources of ecological implausibility in the models in a bag and uses them to remove variables the produce such implausibility. Sources of implausibility might be coefficients with signs opposite to one's hypothesis, response curves crossing zero, or response curves with multiple inflection points, for instance.
Arguments
- x
[bag]
A bag of models, resulting from a call tobag_models().- data
[data.frame]
The original, complete data used for model fitting.- measure
[character(1)="cross"]{"coef_sign", "cross"}
Measure used to quantify ecological implausibility in the model or coefficients, based on the coefficients and the response plots for each type of covariate with zone of influence in a model. It can be one of these:"coef_sign": The measure is based on the minimum ZOI radius for which the sign is opposite to the ecologically expected sign;"cross": default. The measure is based on the minimum distance at which a reponse curve crosses zero.
- criterion
[character(1)="first_coef"]{"min", "first_coef"}
Criterion used to truncate the curves/coefficients, for each type of ZOI variable. Only applicable formeasure = "cross". Ifcriterion = "first_coef"(default), the coefficients are set to zero starting from the first coefficient whose sign is opposite to the expected sign, which is larger than the distance at which the response plot crosses zero for that ZOI variable. Ifcriterion = "min", the coefficients are set to zero for all terms whose radius is larger than the distance at which the response plot crosses zero for that ZOI variable (regardless of the coefficient signs).- wmean
[logical(1)=TRUE]
Whether the truncation should be based on the weighted mean coefficients and response plots (default, ifwmean = TRUE) or on each individual model coefficient and response plots (ifwmean = FALSE).- expected_sign
[numeric(1)=-1]
Expected sign of the coefficient. Either -1 (negative), +1 (positive), or 0 (no effect).- reassess
[logical(1)=TRUE]
Should the model be reassessed after truncation, with fit, calibration, and validation scores re-computed? Default isTRUE.- verbose
[logical(1)=FALSE]
Whether to print progress messages.- ...
[any]
Additional parameters passed toimplausibility().
Value
A modified bag object of the same structure as the input x, with
ecologically implausible coefficients set to zero, and optionally re-evaluated
fit, calibration, and validation scores (if reassess = TRUE).
Details
Currently, this function is applied only to terms corresponding to zones of influence (ZOI). Importantly, this function does not re-fit the model, but only sets coefficients to zero for all ZOI terms above the radius in which a certain implausibility is identified.
Examples
#-------
# fit a bag
#---
# fit a bag to be tested
# load packages
library(glmnet)
# load data
data("reindeer_rsf")
# rename it just for convenience
dat <- reindeer_rsf
# formula initial structure
f <- use ~ private_cabins_cumulative_XXX + public_cabins_high_cumulative_XXX +
trails_cumulative_XXX +
NORUTreclass +
# poly(norway_pca_klima_axis1, 2, raw = TRUE) +
# poly(norway_pca_klima_axis2, 2, raw = TRUE) +
norway_pca_klima_axis1 + norway_pca_klima_axis1_sq +
norway_pca_klima_axis2 + norway_pca_klima_axis2_sq +
norway_pca_klima_axis3 + norway_pca_klima_axis4
# add ZOI terms to the formula
zois <- c(100, 250, 500, 1000, 2500, 5000, 10000, 20000)
ff <- add_zoi_formula(f, zoi_radius = zois, pattern = "XXX",
cumulative = "",
type = c("exp_decay"),#, "nearest_exp_decay"),
separator = "", predictor_table = TRUE)
f <- ff$formula
pred_table <- ff$predictor_table
# sampling - random sampling
set.seed(1234)
samples <- create_resamples(y = dat$use,
p = c(0.2, 0.2, 0.2),
times = 20,
colH0 = NULL)
#> [1] "Starting random sampling..."
# fit multiple models
fittedl <- bag_fit_net_logit(f,
data = dat,
samples = samples,
standardize = "internal", # glmnet does the standardization of covariates
metric = "AUC",
method = "AdaptiveLasso",
predictor_table = pred_table,
parallel = "mclapply",
mc.cores = 8) #2)
# bag models in a single object
bag_object <- bag_models(fittedl, dat, score_threshold = 0.7)
#---------
# truncate model
bag_object_trunc <- truncate_bag(bag_object,
data = dat,
measure = "cross",
criterion = "first_coef",
wmean = FALSE)
#> Error in plot_response(x, dfvar = dfvar, data = data, type = "linear", zoi = TRUE, type_feature_recompute = type_feature_recompute, resolution = resolution, type_feature = type_feat, baseline = baseline, wq_probs = NULL, ci = FALSE, indiv_pred = TRUE, ggplot = FALSE, ...): unused argument (ggplot = FALSE)
# compare validation scores
bag_object$validation_score - bag_object_trunc$validation_score
#> Error: object 'bag_object_trunc' not found
bag_object$weighted_validation_score
#> weighted_validation_score
#> [1,] 0.922617
bag_object_trunc$weighted_validation_score
#> Error: object 'bag_object_trunc' not found
# plot curves to check implausibility
# ZOI public cabins cumulative
dfvar = data.frame(trails_cumulative = 1e3*seq(0.2, 20, length.out = 100))
# look into curve
# plot_response(bag_object,
# dfvar = dfvar,
# data = dat,
# type = "linear", zoi = TRUE,
# type_feature = "line",
# type_feature_recompute = TRUE,
# resolution = 300,
# ci = FALSE, indiv_pred = TRUE)
# original plot
plot_response(bag_object,
dfvar = dfvar,
data = dat,
type = "linear", zoi = TRUE,
ci = FALSE, indiv_pred = TRUE)
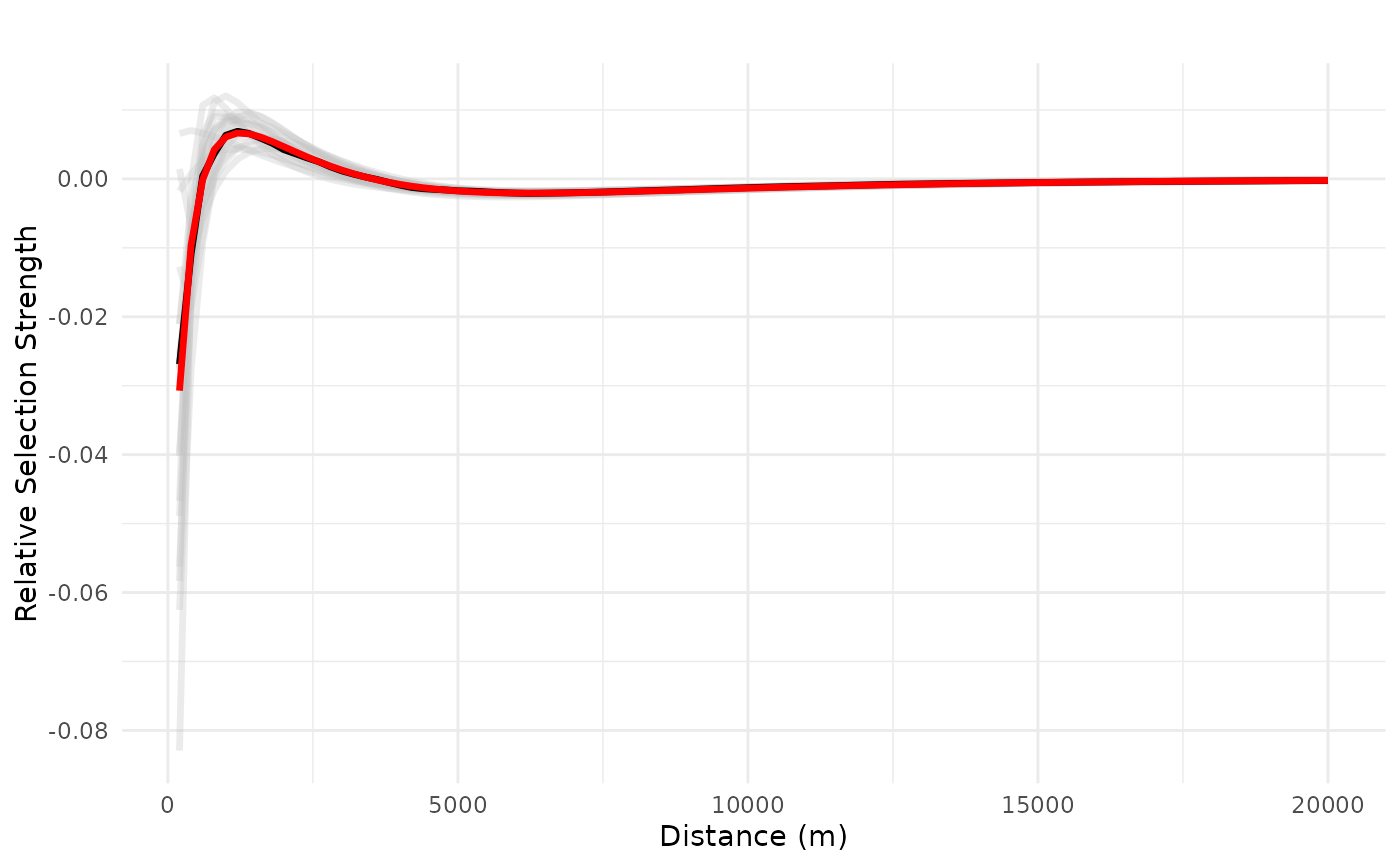 # truncated plot
plot_response(bag_object_trunc,
dfvar = dfvar,
data = dat,
type = "linear", zoi = TRUE,
# type_feature = "line",
# type_feature_recompute = TRUE,
# resolution = 300,
ci = FALSE, indiv_pred = TRUE)
#> Error: object 'bag_object_trunc' not found
# check implausibility
implausibility(bag_object_trunc, dat)
#> Error: object 'bag_object_trunc' not found
# truncated plot
plot_response(bag_object_trunc,
dfvar = dfvar,
data = dat,
type = "linear", zoi = TRUE,
# type_feature = "line",
# type_feature_recompute = TRUE,
# resolution = 300,
ci = FALSE, indiv_pred = TRUE)
#> Error: object 'bag_object_trunc' not found
# check implausibility
implausibility(bag_object_trunc, dat)
#> Error: object 'bag_object_trunc' not found