10 Pressure factor analysis
For every indicator in the NI database, experts have made a qualitative assessment of how important a suite of different pressure factors are for the indicator in question. The evaluated pressure factors included:
- Harvesting and exploitation
- Invasive species
- Acidification
- Eutrophication
- Other pollution
- Climate change
- Land use / reduced habitat quality
- Abandonment of traditional management
- Habitat destruction, incl. infrastructure
- Disturbances by human activities
- Other human pressures
- Hydrological changes
- Unknown or natural processes
In practice, this assessment involved choosing one of the following categories for each pressure:
- Not relevant/unknown
- Very small
- Small
- Moderate
- Strong
- Very strong
Traditionally, an aggregation of this qualitative pressure information has been presented as part of the NI updates. In the following, we run this pressure factor analysis and generate visualization based on it.
The original code underlying this was written by Bård Pedersen and Simon Jakobsson and is archived on NINA’s internal drives under: R:/Prosjekter/12892000_naturindeks_rammeverk_database_og_innsynslosning/Naturindeks/2020/Beregninger/Påvirkningsfaktorer/påvirkningsAnalyse.R
10.2 Assemble indicator x pressure matrices
10.2.1 Assembling basic matrices
First, we build indicator x pressure matrices based on the table “Indikator_paavirkning” in the NI database. This table is not currently available in the API, but we can easily reconstruct it from other, available tables in the database. To do that, we start with downloading the relevant tables from the database:
## Indicator pressures table
# Location of resource - API for T_Skaleringsmodell table in Norwegian NI database
serverUrl <- "https://www8.nina.no/"
APIUrl <- .url
token <- .niToken
methodPath <- "/api/Reference/pressureIndicator"
# Extract content from API
rawContent <- extractContentFromNiapi(APIUrl,methodPath,token,as="text")
# Parse the content into a suitable R object - a data.frame using column names set by the API
indicatorPressure <- jsonlite::fromJSON(rawContent, simplifyDataFrame = TRUE)
## Pressure IDs
methodPath <- "/api/Reference/PressureFactors"
rawContent <- extractContentFromNiapi(APIUrl, methodPath, token, as = "text")
pressureID <- jsonlite::fromJSON(rawContent, simplifyDataFrame = TRUE)
## Pressure values
methodPath <- "/api/Reference/PressureValues"
rawContent <- extractContentFromNiapi(APIUrl, methodPath, token, as = "text")
pressureValues <- jsonlite::fromJSON(rawContent, simplifyDataFrame = TRUE) %>%
dplyr::mutate(id = as.character(id))The table linking indicator IDs and names is already present in our directory, so we retrieve it from there:
Once we have all tables, we combine information to obtain the overview of indicators x pressures including IDs and names:
## Collate data
indicatorPressure <- indicatorPressure %>%
dplyr::left_join(pressureID, by = c("pressureFactorId" = "id")) %>%
dplyr::left_join(pressureValues, by = c("pressureValueId" = "id")) %>%
dplyr::left_join(indicatorList, by = c("indicatorId" = "id")) %>%
dplyr::rename(pressureFactorName = name.x,
pressureFactorName_en = nameEnglish,
pressureFactorAbbr = abbreviation,
pressureValueName = name.y,
indicatorName = name) %>%
dplyr::select(indicatorId, indicatorName, pressureFactorId, pressureFactorName, pressureValueId, pressureValueName)
## Drop inactive indicators
indicatorPressure <- indicatorPressure %>%
dplyr::filter(!is.na(indicatorName))Then, we proceed to restructure this information into indicator x pressureFactor matrices, whose elements represent the pressure Value either in numerical or text format.
## Set up matrices
indicators <- sort(unique(indicatorPressure$indicatorName))
pressures <- sort(unique(indicatorPressure$pressureFactorName))
indicatorPressureMatrix <- matrix("", nrow = length(indicators), ncol = length(pressures))
indicatorPressureMatrixNum <- matrix(NA,nrow = length(indicators), ncol = length(pressures))
dimnames(indicatorPressureMatrix) <- dimnames(indicatorPressureMatrixNum) <- list(indicators,pressures)
## Fill in values
for (i in 1:nrow(indicatorPressure)){
indName_i <- indicatorPressure$indicatorName[i]
pressName_i <- indicatorPressure$pressureFactorName[i]
indicatorPressureMatrix[indName_i, pressName_i] <- indicatorPressure$pressureValueName[i]
indicatorPressureMatrixNum[indName_i, pressName_i] <- as.numeric(indicatorPressure$pressureValueId[i])
}10.2.2 Assigning values to pressure information
In the next step, the values in the numerical matrix are are adjusted by multiplying them by 2 and subtracting 1 (there does not seem to be any documentation available from previous NI updates that details why this is done). In addition, value 0 is assigned to the “not relevant / unknown” type.
10.2.3 Setting up additional aggregate pressure factors
Before proceeding, we now set up a few additional pressure factors that constitute combinations of some of the reported pressure factors. These are created to be largely consistent with the five major pressure factors as fronted by the IPBES:
- changes in land and sea use (“Arealbruk og inngrep”, made up of “Arealbruk”, “Fysiske inngrep”, “Hydrologiske endringer”, and “Opphør av tradisjonell drift”)
- direct exploitation of organisms (= “Beskatning og høsting”)
- climate change (= “Klima”)
- pollution (“Fourensing”, made up of “Eutrofierende stoffer”, “Forsurende stoffer”, and “Annen forurensing”)
- invasive non-native species (= “Fremmede arter”)
The only notable difference relative to IPBES terminology is that here, we consider hydrological changes as “change in land use” instead of “direct exploitation”.
## Set up empty vectors for aggregate pressure factors
forurensing <- arealbrukInngrep <- rep(0, length(indicators))
names(forurensing) <- names(arealbrukInngrep) <- indicators
## Assign pressure factors to aggregate
forurensing_names <- c("Annen forurensning",
"Eutrofierende stoffer",
"Forsurende stoffer")
arealbrukInngrep_names <- c("Arealbruk",
"Opphør av tradisjonell drift",
"Fysiske inngrep","Hydrologiske endringer")
## Aggregate (by choosing max)
suppressWarnings(
for (i in 1:dim(indicatorPressureMatrixNum)[1]) {
forurensing[i] <- max(indicatorPressureMatrixNum[i, forurensing_names], na.rm = TRUE)
arealbrukInngrep[i] <- max(indicatorPressureMatrixNum[i, arealbrukInngrep_names], na.rm = TRUE)
}
)
forurensing[forurensing == -Inf] <- NA
arealbrukInngrep[arealbrukInngrep == -Inf] <- NA
## Add to numerical pressure matrix
namess <- c(dimnames(indicatorPressureMatrixNum)[[2]],"Forurensing","Arealbruk og inngrep")
indicatorPressureMatrixNum <- cbind(indicatorPressureMatrixNum, forurensing, arealbrukInngrep)
dimnames(indicatorPressureMatrixNum)[[2]] <- namess
## Retrieve equivalent pressure value names and add to text pressure matrix
pressureStrengthCategories <- pressureValues$name
pressureStrengthCategoriesNum <- (as.numeric(pressureValues$id)*2)-1
pressureStrengthCategoriesNum[which(pressureStrengthCategoriesNum == 13)] <- 0
forurensingT <- arealbrukInngrepT <- rep("", length(indicators))
names(forurensingT) <- names(arealbrukInngrepT) <- indicators
for (i in 1:length(indicators)){
if (is.na(forurensing[i])){
forurensingT[i] <- NA
}else{
forurensingT[i] <- pressureStrengthCategories[which(pressureStrengthCategoriesNum == forurensing[i])]
}
if (is.na(arealbrukInngrep[i])){
arealbrukInngrepT[i] <- NA
}else{
arealbrukInngrepT[i] <- pressureStrengthCategories[which(pressureStrengthCategoriesNum == arealbrukInngrep[i])]
}
}
namess <- c(dimnames(indicatorPressureMatrix)[[2]], "Forurensing","Arealbruk og inngrep")
indicatorPressureMatrix <- cbind(indicatorPressureMatrix, forurensingT, arealbrukInngrepT)
dimnames(indicatorPressureMatrix)[[2]] <- namessAfter that, we save the indicator pressure data and matrices in the “data” folder.
10.3 Run pressure factor analysis
The pressure factor analysis consists of the following six steps:
- Calculate weight for each indicator observation
- Calculate scaled indicator values
- Estimate indicator contribution as weight x scaled value
- Estimate indicator contribution to NI reduction as weight - contribution
- Summarise contributions to NI reduction across years
- Subset and scale contributions to NI reductions according to relevant pressure factors
10.3.1 Calculation of indicator contributions and NI reductions
Below, we execture steps 1.-4. of the pressure factor analysis:
## Set seed and number of simulations
mySeed <- 1
set.seed(mySeed)
nsim <- 1000
## List ecosystems
ecosystems <- c("Forest", "Mountain", "Wetlands", "OpenLowland",
"Freshwater", "Coast", "Ocean")
ecosystems_no <- awBSunits <- c("Skog", "Fjell", "Våtmark", "Åpent lavland",
"Ferskvann", "Kystvann", "Hav")
## Set up empty list for storing results
pressureResults <- list()
## Make directory for storing results
if(!(dir.exists("results_PressureFactors"))){
dir.create("results_PressureFactors")
}
for (i in 1:length(ecosystems)){
message(paste0("Running pressure factor analysis for ecosystem: ", ecosystems[i]))
## Load in corresponding NI object
eco_NIobject <- readRDS(paste0("data/NI2025_Data_", ecosystems[i], ".rds"))
## Assign data, imputations, and calculation parameters
dataSet <- eco_NIobject$InputData
imputations <- eco_NIobject$NAImputes
awBSunit <- awBSunits[i]
BSunitWeightVariable <- dataSet$BSunits[[which(names(dataSet$BSunits) == awBSunit)]]
nYears <- length(dataSet$indicatorValues)
yearNames <- names(dataSet$indicatorValues)
imputationsPresent <- eco_NIobject$indexInfo$NAImputation
nNIunits <- dim(dataSet$NIunits)[2]
NIunitNames <- dimnames(dataSet$NIunits)[[2]]
ICunitIds <- unique(as.vector(dataSet$ICunits)[!is.na(as.vector(dataSet$ICunits))])
nICunits <- length(ICunitIds)
## List ICunits for all observations and imputations
obs <- imps <- allObs <- NULL
for(t in yearNames){
obss <- dataSet$indicatorValues[[t]]$ICunitId[which((dataSet$indicatorValues[[t]]$expectedValue >= 0) &
(!is.na(dataSet$indicatorValues[[t]]$expectedValue)))]
obs <- c(obs,list(obss))
names(obs)[length(obs)] <- t
}
if(imputationsPresent){
for(t in yearNames){
impss <- imputations$identifiers$ICunitId[imputations$identifiers$year == t]
imps <- c(imps,list(impss))
names(imps)[length(imps)] <- t
}
for(t in yearNames){
allObs[t] <- sum(ICunitIds %in% c(obs[[t]],imps[[t]])) == nICunits
}
}else{
for(t in yearNames){
allObs[t] <- sum(ICunitIds %in% obs[[t]]) == nICunits
}
}
## Retrieve fidelity variable (if present)
if("fidelity" %in% names(dataSet$indicators)){
fidelityVariable <- which(match(names(dataSet$indicators), table = c("fidelity"), nomatch = 0) != 0)
}else{
matchNames <- c("id", "name","keyElement","functionalGroup","functionalGroupId","scalingModel","scalingModelId")
fidelityVariable <- which(match(names(dataSet$indicators), table = matchNames, nomatch = 0) == 0)
}
## Set toggle for fidelity weights
fids <- FALSE
#if (eco == "Kystvann") {fids = TRUE}
#if (eco == "Kystvann-bunn") {fids = TRUE}
# NOTE: I disabled this from the original as it is not documented anywhere why
# fidelity weights should be used for the coastal ecosystem here. Fidelity
# weights have not been used in NI calculations since 2015, not for the coastal
# ecosystem either.
## Calculate NI weights
xxx <- calculateBSunitWeights(ICunits = dataSet$ICunits,
indicators = dataSet$indicators$name,
fidelity = dataSet$indicators[[fidelityVariable]],
trophicGroup = dataSet$indicators$functionalGroup,
keyElement = dataSet$indicators$keyElement,
fids = fids,
tgroups = TRUE,
keys = "specialWeight",
w = 0.5)
yyy <- calculateNIunitWeights(BSunits = dataSet$BSunits$name,
NIunits = dataSet$NIunits,
awbs = TRUE,
awBSunit = BSunitWeightVariable)
NIWeights <- calculateWeights(BSunitWeights = xxx,
NIunitWeights = yyy)
## Sample reference values
refType <- rep("tradObs",length(dataSet$referenceValues$ICunitId))
custom <- !is.na(dataSet$referenceValues$customDistributionUUID)
refType[custom] <- "customObs"
refmat <- sampleObsMat(ICunitId = dataSet$referenceValues$ICunitId,
value = dataSet$referenceValues$expectedValue,
distrib = dataSet$referenceValues$distributionFamilyName,
mu = dataSet$referenceValues$distParameter1,
sig = dataSet$referenceValues$distParameter2,
customDistribution = dataSet$referenceValues$customDistribution,
imputations = NULL,
obsMethod = "constant",
obsType = refType,
impYear = NULL,
nsim = nsim)
ecoresults <- list()
for (t in yearNames){
## Sample indicator observations
obsType <- rep("tradObs", length(c(obs[[t]], imps[[t]])))
custom <- !is.na(dataSet$indicatorValues[[t]]$customDistributionUUID)
obsType[custom] <- "customObs"
obsType[dataSet$indicatorValues[[t]]$ICunitId %in% imps[[t]]] <- "imputations"
bootmat <- sampleObsMat(ICunitId = dataSet$indicatorValues[[t]]$ICunitId,
value = dataSet$indicatorValues[[t]]$expectedValue,
distrib = dataSet$indicatorValues[[t]]$distributionFamilyName,
mu = dataSet$indicatorValues[[t]]$distParameter1,
sig = dataSet$indicatorValues[[t]]$distParameter2,
customDistribution = dataSet$indicatorValues[[t]]$customDistribution,
imputations = imputations,
obsMethod = "sample",
obsType = obsType,
impYear = t,
nsim = nsim)
## Scale indicator observations
refmati <- refmat[as.character(dimnames(bootmat)[[1]]), ]
scaleVec <- dataSet$indicatorValues[[t]]$scalingModel
names(scaleVec) <- dataSet$indicatorValues[[t]]$ICunitId
scaleVec <- scaleVec[dimnames(bootmat)[[1]]]
scaledBootmat <- scaleObsMat(bootmat = bootmat,
refmat = refmati,
scalingModel = scaleVec,
truncAtRef = TRUE)
## Assemble scaled indicator observations in an indicator x ICunit matrix
ICunits <- dataSet$ICunits
scaledObsPerBsunit <- array(0, dim = c(dim(ICunits), nsim))
if(length(dimnames(ICunits)[[1]]) == 1){
dimnames(scaledObsPerBsunit)[[1]] <- list(dimnames(ICunits)[[1]])
}else{
dimnames(scaledObsPerBsunit)[[1]] <- dimnames(ICunits)[[1]]
}
if(length(dimnames(ICunits)[[2]]) == 1){
dimnames(scaledObsPerBsunit)[[2]] <- list(dimnames(ICunits)[[2]])
}else{
dimnames(scaledObsPerBsunit)[[2]] <- dimnames(ICunits)[[2]]
}
dimnames(scaledObsPerBsunit)[[3]] <- 1:nsim
weightedObsPerBsunit <- scaledObsPerBsunit
for(j in dimnames(scaledBootmat)[[1]]){
if(dim(ICunits)[2] == 1) {
k1 <- which(ICunits[,] == j, arr.ind = TRUE)
k2 <- rep(1, length(k1))
k <- as.matrix(cbind(k1, k2))
}else{
k <- which(ICunits[,] == j,arr.ind = TRUE)
}
for(kk in 1:dim(k)[1]){
scaledObsPerBsunit[k[kk, 1], k[kk, 2],] <- scaledBootmat[as.character(j), ]
}
}
## Multiply indicator observations by observation weight
indices <- list()
for(j in names(NIWeights)){
index <- rep(0, dim(scaledBootmat)[2])
for(k in 1:dim(scaledBootmat)[2]){
index[k] <- sum(NIWeights[[j]] * scaledObsPerBsunit[,, k], na.rm = TRUE)
}
indices[[j]] <- index
}
## Calculate contributions to NI (reductions) for each indicator and indicator observation
## Contribution = indicator weight x scaled indicator value
## Reduction = indicator weight - indicator contribution
contributionPerIndicator <- reductionPerIndicator <- matrix(0,
nrow = dim(ICunits)[2],
ncol = nsim,)
dimnames(contributionPerIndicator) <- dimnames(reductionPerIndicator) <- list(dimnames(scaledObsPerBsunit)[[2]],
dimnames(scaledObsPerBsunit)[[3]])
for(k in 1:dim(scaledBootmat)[2]){
weightedObsPerBsunit[,, k] <- NIWeights[[1]] * scaledObsPerBsunit[,, k]
contributionPerIndicator[, k] <- colSums(NIWeights[[1]] * scaledObsPerBsunit[,, k], na.rm = TRUE)
reductionPerIndicator[, k] <- colSums(NIWeights[[1]], na.rm = TRUE) -
colSums(NIWeights[[1]] * scaledObsPerBsunit[,, k], na.rm = TRUE)
}
## Assemble results in a list & save
ecoresults[[t]] <- list(scaledIndicatorObsPerBSunit = scaledObsPerBsunit,
NIWeightsPerBSunit = NIWeights[[1]],
weightedIndicatorObsPerBSunit = weightedObsPerBsunit,
natureIndex = indices[[1]],
weightsPerIndicator = colSums(NIWeights[[1]], na.rm = TRUE),
contributionPerIndicator = contributionPerIndicator,
reductionPerIndicator = reductionPerIndicator)
saveRDS(ecoresults[[t]], file = paste0("results_PressureFactors/pressures_", ecosystems[i], ".rds"))
}
## Add results to list for all ecosystems
pressureResults[[i]] <- ecoresults
}
## Save joint results
saveRDS(pressureResults, file = "results_PressureFactors/pressures_AllEcosystems.rds")10.3.2 Summarising and scaling contributions to NI reduction
In step 5., we average the calculated indicator contributions to NI reduction across all years. In addition, we single out the latest year (2024 as per now) for highlighting:
meanReductionPerIndicator <- reductionPerIndicator_latest <- list()
for(i in 1:length(ecosystems)){
## Extract contributions to reduction per indicator for each year
redPerInd_list <- list()
for(t in 1:length(pressureResults[[i]])){
redPerInd_list[[t]] <- pressureResults[[i]][[t]]$reductionPerIndicator
}
## Average over all years
meanReductionPerIndicator[[i]] <- Reduce("+", redPerInd_list) / length(redPerInd_list)
## Extract latest year
reductionPerIndicator_latest[[i]] <- redPerInd_list[[length(pressureResults[[i]])]]
}Then, in the final step, we re-evaluate the contributions to NI reduction with each indicator’s primary pressure factors in mind. Specifically, for each pressure factor, we summarise the contributions of indicators that are assigned at least a medium (“middels”) level of sensitivity to the specific pressure factor. Notably, the only information on the assigned pressure factor sensitivity levels that we use here is whether or not the assigned level is >= 5. Lower assigned pressure sensitivities are thus ignored, and higher ones do not count more in the current analysis.
meanNIReduction <- NIReduction_latest <- list()
for(i in 1:length(ecosystems)){
reduction <- reduction_latest <- matrix(0, nrow = dim(indicatorPressureMatrixNum)[2], ncol = 3)
dimnames(reduction) <- dimnames(reduction_latest) <- list(dimnames(indicatorPressureMatrixNum)[[2]], c("2.5%","50%","97.5%"))
for(pressure in colnames(indicatorPressureMatrixNum)){
## Select indicators to consider based on pressure scores (only 5 = "middels / medium" are considered)
taMed <- indicatorPressureMatrixNum[which(rownames(indicatorPressureMatrixNum) %in% rownames(meanReductionPerIndicator[[i]])), pressure] >= 5
taMed[is.na(taMed)] <- FALSE
## Summarise pressure contributions
if(sum(taMed) == 0){
reduction[pressure,] <- reduction_latest[pressure,] <- rep(0.0,3)
}else if(sum(taMed) == 1){
reduction[pressure,] <- quantile(meanReductionPerIndicator[[i]][taMed,], c(0.025,0.5,0.975))
reduction_latest[pressure,] <- quantile(reductionPerIndicator_latest[[i]][taMed,], c(0.025,0.5,0.975))
}else{
reduction[pressure,] <- quantile(colSums(meanReductionPerIndicator[[i]][taMed,]), c(0.025,0.5,0.975))
reduction_latest[pressure,] <- quantile(colSums(reductionPerIndicator_latest[[i]][taMed,]), c(0.025,0.5,0.975))
}
}
meanNIReduction[[i]] <- reduction
NIReduction_latest[[i]] <- reduction_latest
}
names(meanNIReduction) <- names(NIReduction_latest) <- ecosystems_no
## Save results (RDS)
saveRDS(meanNIReduction, file = "results_PressureFactors/meanNIReduction.rds")
saveRDS(NIReduction_latest, file = "results_PressureFactors/NIReduction_latest.rds")
## Save results (CSV)
meanNIReduction_table <- NIReduction_latest_table <- data.frame()
for(i in 1:length(ecosystems_no)){
add_data <- tibble::as_tibble(meanNIReduction[[i]]) %>%
dplyr::mutate(Økosystem = ecosystems_no[i],
Påvirkningsfaktor = rownames(meanNIReduction[[i]]),
.before = 1)
meanNIReduction_table <- rbind(meanNIReduction_table, add_data)
add_data_latest <- tibble::as_tibble(NIReduction_latest[[i]]) %>%
dplyr::mutate(Økosystem = ecosystems_no[i],
Påvirkningsfaktor = rownames(NIReduction_latest[[i]]),
.before = 1)
NIReduction_latest_table <- rbind(NIReduction_latest_table, add_data_latest)
}
options(scipen = 999)
meanNIReduction_table <- meanNIReduction_table %>%
dplyr::rename(median = `50%`,
q025 = `2.5%`,
q975 = `97.5%`) %>%
dplyr::mutate(across(c(median, q025, q975), ~ as.character(round(.x, digits = 5)))) %>%
dplyr::select(Økosystem, Påvirkningsfaktor, median, q025, q975)
NIReduction_latest_table <- NIReduction_latest_table %>%
dplyr::rename(median = `50%`,
q025 = `2.5%`,
q975 = `97.5%`) %>%
dplyr::mutate(across(c(median, q025, q975), ~ as.character(round(.x, digits = 5)))) %>%
dplyr::select(Økosystem, Påvirkningsfaktor, median, q025, q975)
readr::write_excel_csv(meanNIReduction_table, "results_PressureFactors/meanNIReduction.csv")
readr::write_excel_csv(NIReduction_latest_table, "results_PressureFactors/NIReduction_latest.csv")10.4 Visualize results
Finally, we plot the relative contributions of the different pressure factor to reductions in NI from the reference state for each ecosystem.
## Select pressures to plot (only five most influential according to IPBES)
meanNIReduction_table <- meanNIReduction_table %>%
dplyr::filter(Påvirkningsfaktor %in% c("Arealbruk og inngrep",
"Klima",
"Beskatning og høsting",
"Forurensing",
"Fremmede arter"))
NIReduction_latest_table <- NIReduction_latest_table %>%
dplyr::filter(Påvirkningsfaktor %in% c("Arealbruk og inngrep",
"Klima",
"Beskatning og høsting",
"Forurensing",
"Fremmede arter"))
## Set factor order for plotting
ecosystem_order <- c("Hav", "Kystvann", "Ferskvann", "Våtmark", "Skog", "Fjell", "Åpent lavland")
pressure_order <- c("Arealbruk og inngrep", "Klima", "Beskatning og høsting", "Forurensing", "Fremmede arter")
meanNIReduction_table <- meanNIReduction_table %>%
dplyr::mutate(Økosystem = factor(Økosystem, levels = ecosystem_order),
Påvirkningsfaktor = factor(Påvirkningsfaktor, levels = pressure_order))
NIReduction_latest_table <-NIReduction_latest_table %>%
dplyr::mutate(Økosystem = factor(Økosystem, levels = ecosystem_order),
Påvirkningsfaktor = factor(Påvirkningsfaktor, levels = pressure_order))
## Set color palette
plot.palette <- c("#9DB751", "#68C3CD", "#283D4E", "#D0D0D0", "#CF8713")
## Plot for overall mean
p_mean <- ggplot(meanNIReduction_table) +
geom_bar(aes(x = Økosystem, y = median, fill = Påvirkningsfaktor), stat = "identity", position = "dodge") +
scale_fill_manual(values = plot.palette) +
xlab("") +
ggtitle("Gjennomsnitt (2000-2024)") +
ylab("Reduksjon i indeksverdi") +
theme_classic() + theme(plot.title = element_text(hjust = 0.5))
p_mean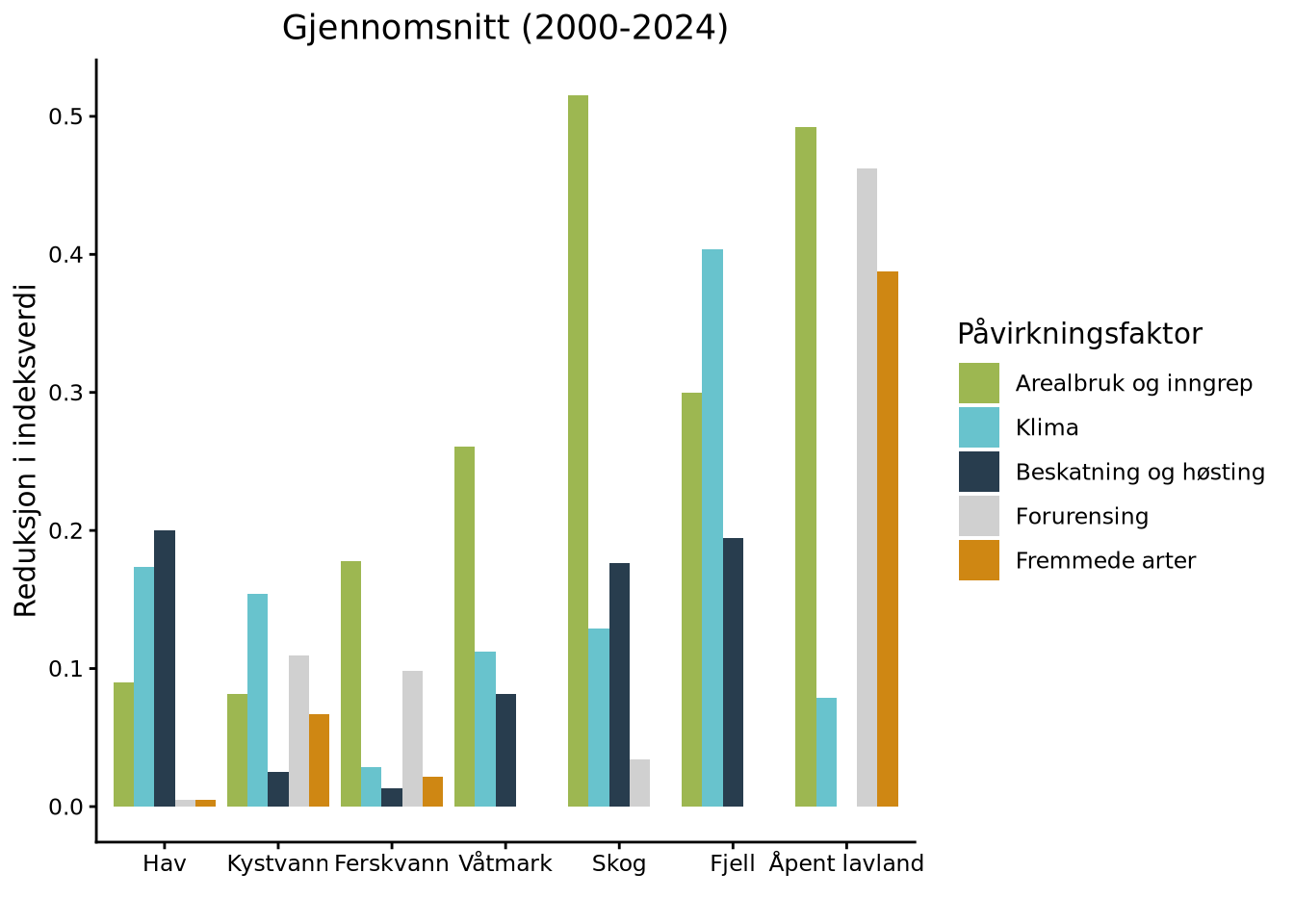
ggsave(file = "results_PressureFactors/PressureFactors_average.svg", plot = p_mean, width = 8, height = 4)
ggsave(file = "results_PressureFactors/PressureFactors_average.pdf", plot = p_mean, width = 8, height = 4)
ggsave(file = "results_PressureFactors/PressureFactors_average.png", plot = p_mean, width = 8, height = 4, dpi = 150)## Plot for latest year
p_latest <- ggplot(NIReduction_latest_table) +
geom_bar(aes(x = Økosystem, y = median, fill = Påvirkningsfaktor), stat = "identity", position = "dodge") +
scale_fill_manual(values = plot.palette) +
xlab("") +
ggtitle("2024") +
ylab("Reduksjon i indeksverdi") +
theme_classic() + theme(plot.title = element_text(hjust = 0.5))
p_latest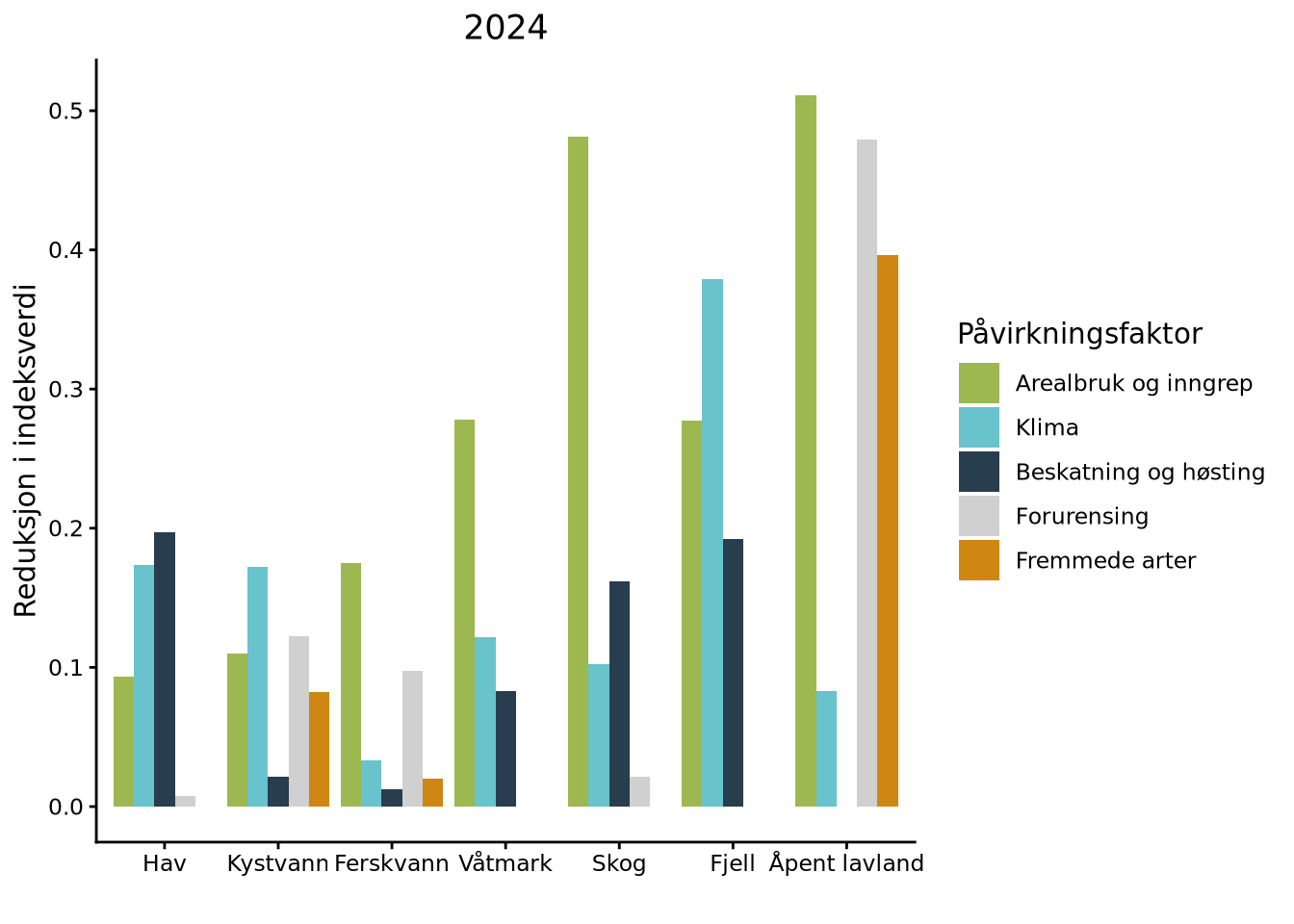
ggsave(file = "results_PressureFactors/PressureFactors_2024.svg", plot = p_latest, width = 8, height = 4)
ggsave(file = "results_PressureFactors/PressureFactors_2024.pdf", plot = p_latest, width = 8, height = 4)
ggsave(file = "results_PressureFactors/PressureFactors_2024.png", plot = p_latest, width = 8, height = 4, dpi = 150)When presenting and interpreting these results/graphs, it’s important to remember a few things:
- The graph visualizes each pressure factor’s contribution to reduction in NI relative to the reference state
- The higher the bar, the larger the negative effect on NI
- The effects of different pressure factors cannot be summed (and do not sum to deviation of NI from 1) as several indicators are sensitive for multiple pressure factors
- The underlying information is each expert’s assessment of indicator sensitivity to the different pressure factors
- Consequently, this is a qualitative, not a quantitative, assessment and should be interpreted as such