13 NDVI - Naturally Open Ecosystems
Norwegian name: Primærproduksjon
NDVI (greenness) indicator, naturally open ecosystems below the treeline
Author and date:
Joachim Töpper, Tessa Bargmann
September 2023
Ecosystem |
Økologisk egenskap |
ECT class |
|---|---|---|
naturlig åpen |
Primærproduksjon |
Structural state characteristics |
13.1 Introduction
The Normalized difference vegetation index (NDVI) can be used to describe the greenness of an area, and may thus represent a proxy for the amount of chlorophyll and plant productivity in the given area. Different ecosystem types naturally have greenness signals of different intensity but also with a certain variance. Deviations beyond the natural variation in either direction may indicate a reduction in ecological condition of a given ecosystem. E.g. lower than normal NDVI may indicate excessive disturbance, while higher than normal NDVI may indicate regrowth and transitions towards more densely vegetated systems. In recent assessments of ecological condition for forest and mountain ecosystems, two different NDVI-based indicators were developed and applied. For forests, NDVI-values across the country were compared to a spatial reference NDVI-signal from protected areas (Framstad et al. 2020). For mountains, the extent and consistence of the temporal change of NDVI-values over the last twenty years was assessed (Framstad et al 2021). In both cases, the NDVI-product from the MODIS satellite reflectance imagery was used based on available maps of spatial ecosystem extent in Norway (i.e. national maps for the forest and mountain ecosystems).
Here, we explore the potential for developing an NDVI-indicator for ecological condition representing naturally open ecosystems below the treeline (called natopen hereafter). For this task, three initial challenges can be identified early on:
- We don’t yet have a national map for natopen ecosystems, i.e. we don’t know the exact locations of all natopen areas in Norway, which is a prerequisite to extract satellite data for the right locations and ecosystems, and thus achieve a good and unbiased spatial representation for the assessment area.
- The spatial extent of the single natopen ecosystem occurrences (hereafter polygons) includes many areas which are way smaller than the pixel size in the MODIS imagery (250 x 250 m) which was used for forests and mountains and has a time series back to year 2000.
- Natopen ecosystems in Norway are widely different in their physiognomy, ecology, and thus vegetation, spanning from highly disturbed hill slopes with sparse ruderal vegetation to nutrient rich shallow soils with resource demanding plant species. Thus, large variation in NDVI signals from different natopen ecosystem types has to be expected.
In this draft development for a NDVI indicator for ecological condition in natopen systems we approach these challenges in the following ways:
- We use ecosystem occurrence data from NiN-mapping to guide the extraction of satellite NDVI data for pixels representing the right ecosystem. However, the ecosystem occurrences in the NiN data are highly spatially biased and thus cannot provide a good and unbiased spatial representation for the assessment area. Our work therefore represents a concept and method development which may be applied in an assessment of ecological condition once spatially unbiased occurrence data or a national map of natopen ecosystems are available.
- We include Sentinel-2 imagery for natopen ecosystems as the resolution for the bands underlying the NDVI product here is 10 x 10 m which is smaller than almost all natopen polygons in the NiN-data. However, since Sentinel-2 only goes back to 2015, we lose much of the time series aspect as compared to the MODIS data. In addition, we include Landsat imagery which goes back to 1984 and has a resolution of 30 x 30 m, but also has more variable data due to less frequent seasonal measurements. We also still explore NDVI data from MODIS (see more details below).
13.2 About the underlying data
In the NDVI project for natopen systems, we use two kinds of data (coming as four datasets) for building indicators for ecological condition:
- NiN ecosystem data from ‘Naturtypekartlegging etter Miljødirektoratets instruks’ to guide extraction of NDVI data for the right locations and to provide information on the field-assessed ecological condition of mapped polygons
- remote sensed NDVI data
- Sentinel-2 satellite NDVI data
- MODIS satellite NDVI data
- Landsat satellite NDVI data
NiN ecosystem data: The NiN data in this study contain data about the ecosystem categories (cf. Halvorsen et al. 2020) present at mapped sites as wall as their spatial delimitation (in the form of polygons). Since we use NiN data that were collected following ‘Miljødirektoratets instruks’, these data also include information on the ecological condition and underlying condition variabels of the mapped sites (see the Miljødirektoratets mapping manual for details). Polygon sizes in these NiN data may vary from <100 sqm to 240 000 sqm.
NDVI data: The NDVI data used in the work at hand are pixel means for polygons in the NiN-data, i.e. each NiN polygon is represented by one NDVI value per measurement time (see below for more details on the temporal resolution of NDVI data). With respect to that, it does only make sense to use NDVI data for polygons that are at least of the same size as the resolution of the respective satellite, and thus we excluded any polygons smaller than each satellite’s resolution.
(2a) Sentinel-2 satellite NDVI data: The Sentinel data have a resolution of 10 x 10 m, and we thus excluded all NiN-polygons smaller than 100 sqm. Sentinel-2 has a revisit frequency of 10 days and should thus provide enough measurements during peak growing season to provide a robust measure of maximum greenness.
(2b) MODIS satellite NDVI data: The MODIS data have a resolution of 250 x 250 m, and we thus excluded all NiN-polygons smaller than 62500 sqm. MODIS has a revisit frequency of 1-2 days and thus provides an extensive sample to provide a robust measure of maximum greenness.
(2c) Landsat satellite NDVI data: The Landsat data have a resolution of 30 x 30 m, and we thus excluded all NiN-polygons smaller than 900 sqm. Landsat has a revisit frequency of 16 days and thus provides the poorest growing season sample among the available NDVI data for a robust measure of maximum greenness.
13.2.1 Representativity in time and space
For natopen systems, the NiN data contain 2881 natopen polygons of known area size across mainland Norway. However, NiN-mapping is not planned and performed in a spatially representative way and thus both the ecosystem occurrences and their spatial extent have to be treated as spatially biased. The 2881 natopen polygons are distributed across regions and major ecosystem types in the following way:
| Region | T2 | T12 | T18 | T20 | T21 |
|---|---|---|---|---|---|
| Northern Norway | 0 | 230 | 648 | 10 | 31 |
| Central Norway | 41 | 282 | 201 | 0 | 0 |
| Western Norway | 49 | 44 | 79 | 0 | 9 |
| Eastern Norway | 217 | 84 | 483 | 2 | 51 |
| Southern Norway | 52 | 155 | 21 | 0 | 73 |
In addition, there is 54 T2s, 57 T12s, 3 T18s, and 5 T21s that are not assigned to any region. (These polygons likely lie in water and thus outside of the regional polygons due to imprecise coordinates from the mapping device).
The NDVI data from either satellite follow the spatial distribution and bias status of the NiN-data. Due to the larger number of excluded polygons in the NDVI data from MODIS (because of the large pixel size in MODIS, see above), the MODIS NDVI data for the natopen occurrences in the NiN data are likely even more spatially biased than it is the case for the NDVI data from Sentinel-2 and Landsat.
13.2.2 Temporal coverage
The currently available NiN data on natopen ecosystems span a time period from 2018-2021 and thus represent a contemporary sample of ecosystem occurrences. Note that none of the polygons in the NiN-data has been visited more than once during that period.
- Available Sentinel-2 satellite NDVI data span the years 2015-2022.
- Available MODIS satellite NDVI data span the years 2000-2022.
- Available Landsat satellite NDVI data span the years 1984-2021.
13.3 Collinearities with other indicators
Unlike wetlands and semi.natural systems, natopen areas are not subject to shrub and tree encroachment due to changes in land-use, Thus, we do not expect any co-linearity of the NDVI signal with e.g. the re-growth indicator based on LiDAr derived canopy height.
13.4 Reference state and values
13.4.1 Reference state and scaling values
This indicator project is mainly exploratory, mapping the possibilities of and lacking prerequisites for satellite derived NDVI data to inform ecological condition assessments. Therefore, we lack a concise strategy for how to define the reference state, especially prior to having access to an ecosystem map for natopen ecosystems (cf. Jakobsson et al. 2020, Töpper & Jakobsson 2021). In this exploratory work, we will use the condition classification in the NiN-data to explore 1. how NDVI connects to natopen ecology and condition and 2. its applicability for defining a reference state.
We will use statistical models to test whether or not NDVI varies systematically with condition and across time.
13.5 Uncertainties
Given a condition index can be achieved, we can calculate a mean indicator value (after scaling) for every region (or any other delimited area of interest) as well as its corresponding standard error and standard deviation as a measure of spatial uncertainty for a geographical area (see Töpper & Jakobsson 2021).
13.6 References
Framstad, E., Kolstad, A. L., Nybø, S., Töpper, J. & Vandvik, V. 2022. The condition of forest and mountain ecosystems in Norway. Assessment by the IBECA method. NINA Report 2100. Norwegian Institute for Nature Research.
Halvorsen, R., Skarpaas, O., Bryn, A., Bratli, H., Erikstad, L., Simensen, T., & Lieungh, E. (2020). Towards a systematics of ecodiversity: The EcoSyst framework. Global Ecology and Biogeography, 29(11), 1887-1906. doi:10.1111/geb.13164
Jakobsson, S., Töpper, J.P., Evju, M., Framstad, E., Lyngstad, A., Pedersen, B., Sickel, H., Sverdrup-Thygeson, A., Vandvik. V., Velle, L.G., Aarrestad, P.A. & Nybø, S. 2020. Setting reference levels and limits for good ecological condition in terrestrial ecosystems. Insights from a case study based on the IBECA approach. Ecological Indicators 116: 106492.
Miljødiretoratets mapping manual: https://www.miljodirektoratet.no/publikasjoner/2022/januar/kartleggingsinstruks-kartlegging-av-terrestriske-naturtyper-etter-nin/
Töpper, J. & Jakobsson, S. 2021. The Index-Based Ecological Condition Assessment (IBECA) - Technical protocol, version 1.0. NINA Report 1967. Norwegian Institute for Nature Research.
13.7 Analyses
13.7.1 Data sets
The analyses in this document make use of the following data sets:
- NiN data (Naturtyper etter Miljødirektoratets instruks)
- Sentinel-2 NDVI data
- MODIS NDVI data
- Landsat NDVI data
13.7.1.1 NiN data and geometry for Norway and the five regions
We read the NiN data for this document from a cache at the NINA server…
…but it can also be directly downloaded from Miljødirektoratets kartkatalog (https://kartkatalog.miljodirektoratet.no/Dataset)
url <- "https://nedlasting.miljodirektoratet.no/Miljodata//Naturtyper_nin/FILEGDB/4326/Naturtyper_nin_0000_norge_4326_FILEGDB.zip"
download(url, dest = "P:/41201785_okologisk_tilstand_2022_2023/data/Naturtyper_nin_0000_norge_4326_FILEGDB.zip", mode = "wb")
unzip("P:/41201785_okologisk_tilstand_2022_2023/data/Naturtyper_nin_0000_norge_4326_FILEGDB.zip",
exdir = "P:/41201785_okologisk_tilstand_2022_2023/data/nin_data"
)
st_layers("P:/41201785_okologisk_tilstand_2022_2023/data/nin_data/Naturtyper_nin_0000_norge_4326_FILEGDB.gdb")
nin <- st_read("P:/41201785_okologisk_tilstand_2022_2023/data/nin_data/Naturtyper_nin_0000_norge_4326_FILEGDB.gdb",
layer = "naturtyper_nin_omr"
)And we upload maps for Norway and the five regions: Southern, Western, Eastern, Central, and Northern Norway
# Import region- og Norgeskart, make sure they have the same geometry as the nin data
nor <- st_read("data/outlineOfNorway_EPSG25833.shp") %>%
st_as_sf() %>%
st_transform(crs = st_crs(nin))
#> Reading layer `outlineOfNorway_EPSG25833' from data source
#> `/data/Egenutvikling/41001581_egenutvikling_anders_kolstad/github/ecosystemCondition_v2/data/outlineOfNorway_EPSG25833.shp'
#> using driver `ESRI Shapefile'
#> Simple feature collection with 1 feature and 2 fields
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: -113472.7 ymin: 6448359 xmax: 1114618 ymax: 7939917
#> Projected CRS: ETRS89 / UTM zone 33N
reg <- st_read("data/regions.shp") %>%
st_as_sf() %>%
st_transform(crs = st_crs(nin))
#> Reading layer `regions' from data source
#> `/data/Egenutvikling/41001581_egenutvikling_anders_kolstad/github/ecosystemCondition_v2/data/regions.shp'
#> using driver `ESRI Shapefile'
#> Simple feature collection with 5 features and 2 fields
#> Geometry type: POLYGON
#> Dimension: XY
#> Bounding box: xmin: -99551.21 ymin: 6426048 xmax: 1121941 ymax: 7962744
#> Projected CRS: ETRS89 / UTM zone 33N
# change region names to something R-friendly
# reg$region
reg$region <- c("Northern Norway", "Central Norway", "Eastern Norway", "Western Norway", "Southern Norway")
# combine the Norway and the region maps
regnor <- st_intersection(reg, nor)13.7.1.2 NDVI data
All NDVI data are calculated mean NDVI values for each respective NiN polygon from each available Sentinel-2, MODIS, or Landsat image in Google Earth Engine (GEE).
13.7.1.2.1 Sentinel-2 NDVI data
The GEE code can be seen here: https://code.earthengine.google.com/2ceb0c3e03adade9e6f6d0903184b8c4 The image collection contains Sentinel imagery from June, July and August 2015-2022 To not exceed GEE memory limits, the exported files had to be iterated over a grid which resulted in 42 separate csv files. This script merges them and then merges the dataframe to the NiN data.
# Import Sentinel NDVI Data
df.s <- list.files("P:/41201785_okologisk_tilstand_2022_2023/data/NDVI_åpenlavland/NDVI_data_Sentinel/", pattern = "*.csv", full.names = TRUE) %>%
map_df(~ fread(.))13.7.1.2.2 MODIS NDVI data
The GEE code can be seen here: https://code.earthengine.google.com/efb84013701f1d5f6e1e81345f389b84 The image collection contains MODIS imagery from June, July and August 2000-2022
# Import MODIS NDVI Data
# MODIS NDVI is scaled by 0.0001. Mean must be divided by 10000.
df.m <- read.csv("/data/P-Prosjekter2/41201785_okologisk_tilstand_2022_2023/data/NDVI_åpenlavland/NDVI_data_MODIS/modis_ndvi_ts_2000_2022.csv")
df.m$mean <- df.m$mean / 1000013.7.1.2.3 Landsat NDVI data
The GEE code can be seen here: https://code.earthengine.google.com/da8a9279238ef26d14be08a43788b6b7 The image collection contains Landsat imagery from June, July and August 1984-2022 To not exceed GEE memory limits, the exported files had to be iterated over a grid which resulted in 42 separate csv files. This script merges them and then merges the dataframe to the NiN data.
# Import Landsat NDVI Data
# Set up conditional file paths
dir <- substr(getwd(), 1, 2)
path <- ifelse(dir == "C:",
"R:/GeoSpatialData/Habitats_biotopes/Norway_Miljodirektoratet_Naturtyper_nin/Original/versjon20221231/Natur_Naturtyper_nin_norge_med_svalbard_25833/Natur_Naturtyper_NiN_norge_med_svalbard_25833.gdb",
"/data/R/GeoSpatialData/Habitats_biotopes/Norway_Miljodirektoratet_Naturtyper_nin/Original/versjon20221231/Natur_Naturtyper_nin_norge_med_svalbard_25833/Natur_Naturtyper_NiN_norge_med_svalbard_25833.gdb"
)
pData <- ifelse(dir == "C:",
"P:/41201785_okologisk_tilstand_2022_2023/data/NDVI_åpenlavland/NDVI_data_Landsat",
"/data/P-Prosjekter2/41201785_okologisk_tilstand_2022_2023/data/NDVI_åpenlavland/NDVI_data_Landsat"
)
# Fread doesn't like the weird path to the server version of the P drive
# hence this horrendous work around
files <- list.files(pData, pattern = "*.csv", full.names = TRUE)
df_list <- list() # initialise a list of dataframes
# read in a dataframe in each slot of the df_list
for (i in files) {
name <- gsub("-", ".", i)
name <- gsub(".csv", "", name)
i <- paste(i, sep = "")
df_list[[i]] <- assign(name, read.csv(i, header = TRUE))
}
df.l <- bind_rows(df_list, .id = "column_label")13.7.2 Data handling
13.7.2.1 NiN data
# fixing variable- and ecosystem-names with special characters
colnames(nin)
colnames(nin)[c(3, 8, 17, 26, 31, 33, 34)] <- c(
"hovedoekosystem", "kartleggingsaar", "noyaktighet",
"omraadenavn", "uk_naertruet", "uk_sentraloekosystemfunksjon",
"uk_spesieltdaarligkartlagt"
)
unique(nin$hovedoekosystem)
nin <- nin %>%
mutate(hovedoekosystem = recode(hovedoekosystem,
"Våtmark" = "Vaatmark",
"Semi-naturlig mark" = "Semi_naturlig",
"Naturlig åpne områder i lavlandet" = "Naturlig-aapent",
"Naturlig åpne områder under skoggrensa" = "Naturlig_aapent"
)) %>%
mutate(validGeo = st_is_valid(SHAPE))
# checking how many polygons have multiple ecosystem types
unique(nin$ninkartleggingsenheter)
nrow(nin)
# 95469 polygons altogether
nrow(nin %>%
filter(grepl(",", ninkartleggingsenheter)))
# 21094 polygons have more than 1 ecosystem type (they are separated by commas in the ninkartleggingsenheter-variable)
nrow(nin %>%
filter(!grepl(",", ninkartleggingsenheter)))
# 74375 polygons should have only 1 ecosystem type
# there's no information on the proportion of ecosystem types in the polygons, so we got to omit all polygons with multiple ecosystem types :(
nin <- nin %>%
filter(!grepl(",", ninkartleggingsenheter))
# fix the content in the ninkartleggingsenheter-variable
summary(as.factor(nin$ninkartleggingsenheter))
# get rid of the NA- in the beginning
nin <- nin %>% mutate(ninkartleggingsenheter = str_remove(ninkartleggingsenheter, "NA_"))
# making a main ecosystem type variable
nin <- nin %>% mutate(
hovedtype = substr(ninkartleggingsenheter, 1, 3),
hovedtype = str_remove(hovedtype, "-")
)
# checking mapping unit against main ecosystem type
nin[, c("hovedoekosystem", "hovedtype")]
summary(as.factor(nin$hovedtype[nin$hovedoekosystem == "Vaatmark"]))
summary(as.factor(nin$hovedtype[nin$hovedoekosystem == "Semi_naturlig"]))
summary(as.factor(nin$hovedtype[nin$hovedoekosystem == "Naturlig_aapne"]))
summary(as.factor(nin$hovedtype[nin$hovedoekosystem == "Skog"]))
summary(as.factor(nin$hovedtype[nin$hovedoekosystem == "Fjell"]))
# making a new variable for the overarching ecosystem types based on the main ecosystem types
nin$hovedoekosystem.orig <- nin$hovedoekosystem
nin <- nin %>%
mutate(hovedoekosystem = case_when(
hovedtype %in% paste("V", c(1, 3:7, 9:10), sep = "") ~ "Vaatmark",
hovedtype %in% paste("V", 11:13, sep = "") ~ "Vaatmark_sterkt_endret",
hovedtype %in% paste("T", c(31:34, 40:41), sep = "") ~ "Semi_naturlig",
hovedtype %in% paste("T", c(2, 12, 18, 20:21), sep = "") ~ "Naturlig_aapent",
hovedtype %in% c(paste("T", c(4, 30, 38), sep = ""), paste("V", c(2, 8), sep = "")) ~ "Skog",
hovedtype %in% c(paste("T", c(3, 7, 9, 10, 14, 22, 26), sep = ""), paste("V", c(6, 7), sep = "")) ~ "Fjell",
TRUE ~ "NA"
))
summary(as.factor(nin$tilstand))
nin <- nin %>% mutate(tilstand = recode(tilstand,
"Dårlig" = "Redusert",
"Svært redusert" = "Svaert_redusert"
))
nin <- nin %>% mutate(tilstand_num = recode(tilstand,
"God" = 0, "Moderat" = 1,
"Redusert" = 2, "Svaert_redusert" = 3
))
summary(as.factor(nin$tilstand))
summary(as.numeric(nin$tilstand_num))
## filter out only natopen data
nin.natopen <- nin %>%
filter(hovedoekosystem %in% c("Naturlig_aapent")) %>%
mutate(id = identifikasjon_lokalid) %>%
filter(validGeo) %>%
drop_na(tilstand) %>%
dplyr::select(id, hovedoekosystem, hovedtype, ninkartleggingsenheter, lokalitetskvalitet, tilstand, tilstand_num, ninbeskrivelsesvariabler, kartleggingsaar)
# merge NiN-data with region
nin.natopen <- st_join(nin.natopen, regnor, left = TRUE)
nin.natopen
colnames(nin.natopen)[c(1, 10)] <- c("id", "region_id")
# check that every nin-polygon still occurs only once
summary(as.factor(nin.natopen$id)) # ok
nin.natopen <- nin.natopen %>%
mutate(area_meters_nin = st_area(nin.natopen))
# check and edit the order of regions
levels(nin.natopen$region)
nin.natopen$region <- as.factor(nin.natopen$region)
levels(nin.natopen$region)
nin.natopen$region <- factor(nin.natopen$region, levels = c("Northern Norway", "Central Norway", "Eastern Norway", "Western Norway", "Southern Norway"))
levels(nin.natopen$region)
# splitting content in the ninbeskrivelsesvariabler-column into separate rows per variable and then separating that column into two for the variable name and value
nin.natopen2 <- nin.natopen %>%
separate_rows(ninbeskrivelsesvariabler, sep = ",") %>%
separate(
col = ninbeskrivelsesvariabler,
into = c("NiN_variable_code", "NiN_variable_value"),
sep = "_",
remove = F
) %>%
mutate(NiN_variable_value = as.numeric(NiN_variable_value)) %>%
mutate(NiN_variable_code = as.factor(NiN_variable_code)) %>%
subset(select = -ninbeskrivelsesvariabler)
nin.natopen2 <- as.data.frame(nin.natopen2)13.7.2.2 NDVI data
## Sentinel-2
# join nin.natopen & Sentinel NDVI data
SentinelNDVI.natopen <- full_join(nin.natopen, df.s, by = "id")
# summary(SentinelNDVI.natopen)
SentinelNDVI.natopen <- SentinelNDVI.natopen %>%
mutate(
hovedoekosystem = as.factor(hovedoekosystem),
hovedtype = as.factor(hovedtype),
ninkartleggingsenheter = as.factor(ninkartleggingsenheter),
lokalitetskvalitet = as.factor(lokalitetskvalitet),
tilstand = as.factor(tilstand),
area_meters = st_area(SentinelNDVI.natopen)
)
# summary(SentinelNDVI.natopen)
# get rid of NAs (i.e. NDVI cells that were not in natopen polygons)
SentinelNDVI.natopen <- SentinelNDVI.natopen %>% filter(!is.na(hovedtype))
SentinelNDVI.natopen <- SentinelNDVI.natopen %>% filter(!is.na(mean))
# summary(SentinelNDVI.natopen)
# get rid of any nin-polygons smaller than the Sentinel grid cell size (100 sqm)
# dim(SentinelNDVI.natopen)
SentinelNDVI.natopen <- SentinelNDVI.natopen %>% filter(as.numeric(area_meters) >= 100)
# dim(SentinelNDVI.natopen)
# split date into year, month & day
SentinelNDVI.natopen <- SentinelNDVI.natopen %>%
dplyr::mutate(
year = lubridate::year(date),
month = lubridate::month(date),
day = lubridate::day(date)
)
# add column for sub-ecosystem types
SentinelNDVI.natopen <- SentinelNDVI.natopen %>% mutate(
subtype = substring(ninkartleggingsenheter, 4),
subtype = str_remove(subtype, "-"),
subtype = str_remove(subtype, "-")
)
# we are using max NDVI per year in every NiN polygon
SentinelNDVI.natopen <- SentinelNDVI.natopen %>%
group_by(id, year) %>%
filter(mean == max(mean, na.rm = TRUE))
# summary(SentinelNDVI.natopen)
## MODIS
# join nin.natopen and Modis NDVI data
ModisNDVI.natopen <- full_join(nin.natopen, df.m, by = "id")
# summary(ModisNDVI.natopen)
ModisNDVI.natopen <- ModisNDVI.natopen %>%
mutate(
hovedoekosystem = as.factor(hovedoekosystem),
hovedtype = as.factor(hovedtype),
ninkartleggingsenheter = as.factor(ninkartleggingsenheter),
lokalitetskvalitet = as.factor(lokalitetskvalitet),
tilstand = as.factor(tilstand),
area_meters = st_area(ModisNDVI.natopen)
)
# summary(ModisNDVI.natopen)
# get rid of NAs (i.e. NDVI cells that were not in natopen polygons)
ModisNDVI.natopen <- ModisNDVI.natopen %>% filter(!is.na(hovedtype))
ModisNDVI.natopen <- ModisNDVI.natopen %>% filter(!is.na(mean))
# summary(ModisNDVI.natopen)
# get rid of any nin-polygons smaller than the Modis grid cell size (62500 sqm)
# dim(ModisNDVI.natopen)
ModisNDVI.natopen <- ModisNDVI.natopen %>% filter(as.numeric(area_meters) >= 62500)
# dim(ModisNDVI.natopen)
# split date into year, month & day
ModisNDVI.natopen <- ModisNDVI.natopen %>%
dplyr::mutate(
year = lubridate::year(date),
month = lubridate::month(date),
day = lubridate::day(date)
)
# we are using max NDVI per year in every NiN polygon
ModisNDVI.natopen <- ModisNDVI.natopen %>%
group_by(id, year) %>%
filter(mean == max(mean, na.rm = TRUE))
# summary(ModisNDVI.natopen)
## Landsat
# join nin.natopen & Landsat NDVI data
LandsatNDVI.natopen <- full_join(nin.natopen, df.l, by = "id")
# summary(LandsatNDVI.natopen)
LandsatNDVI.natopen <- LandsatNDVI.natopen %>%
mutate(
hovedoekosystem = as.factor(hovedoekosystem),
hovedtype = as.factor(hovedtype),
ninkartleggingsenheter = as.factor(ninkartleggingsenheter),
lokalitetskvalitet = as.factor(lokalitetskvalitet),
tilstand = as.factor(tilstand),
area_meters = st_area(LandsatNDVI.natopen)
)
# summary(LandsatNDVI.natopen)
# get rid of NAs (i.e. NDVI cells that were not in natopen polygons)
LandsatNDVI.natopen <- LandsatNDVI.natopen %>% filter(!is.na(hovedtype))
LandsatNDVI.natopen <- LandsatNDVI.natopen %>% filter(!is.na(mean))
# summary(LandsatNDVI.natopen)
# get rid of any nin-polygons smaller than the Landsat grid cell size (900 sqm)
# dim(LandsatNDVI.natopen)
LandsatNDVI.natopen <- LandsatNDVI.natopen %>% filter(as.numeric(area_meters) >= 900)
# dim(LandsatNDVI.natopen)
# split date into year, month & day
LandsatNDVI.natopen <- LandsatNDVI.natopen %>%
dplyr::mutate(
year = lubridate::year(date),
month = lubridate::month(date),
day = lubridate::day(date)
)
# we are using max NDVI per year in every NiN polygon
LandsatNDVI.natopen <- LandsatNDVI.natopen %>%
group_by(id, year) %>%
filter(mean == max(mean, na.rm = TRUE))
# summary(LandsatNDVI.natopen)13.7.3 Exploratory analyses, Sentinel-2
Where are the natopen sites?
tm_shape(regnor) +
tm_fill("GID_0", labels = "", title = "", legend.show = FALSE, alpha=0) +
tm_borders() +
tm_shape(SentinelNDVI.natopen) +
tm_dots("hovedtype", midpoint = NA, palette = tmaptools::get_brewer_pal("YlOrRd", 5, plot = FALSE), scale = 2.5, legend.show = FALSE) +
tm_add_legend(
type = "symbol",
col = tmaptools::get_brewer_pal("YlOrRd", 5, plot = FALSE),
labels = c(
"T12",
"T18",
"T2",
"T20",
"T21"
),
title = "Major ecosystem type",
size = 1.5
) +
tm_layout(
main.title = "Naturally open ecosystems below \nthe tree line \n(NiN, Miljødirektoratets instruks)",
main.title.size = 1.2, legend.position = c("right", "bottom"),
legend.text.size = 1.3, legend.title.size = 1.4
)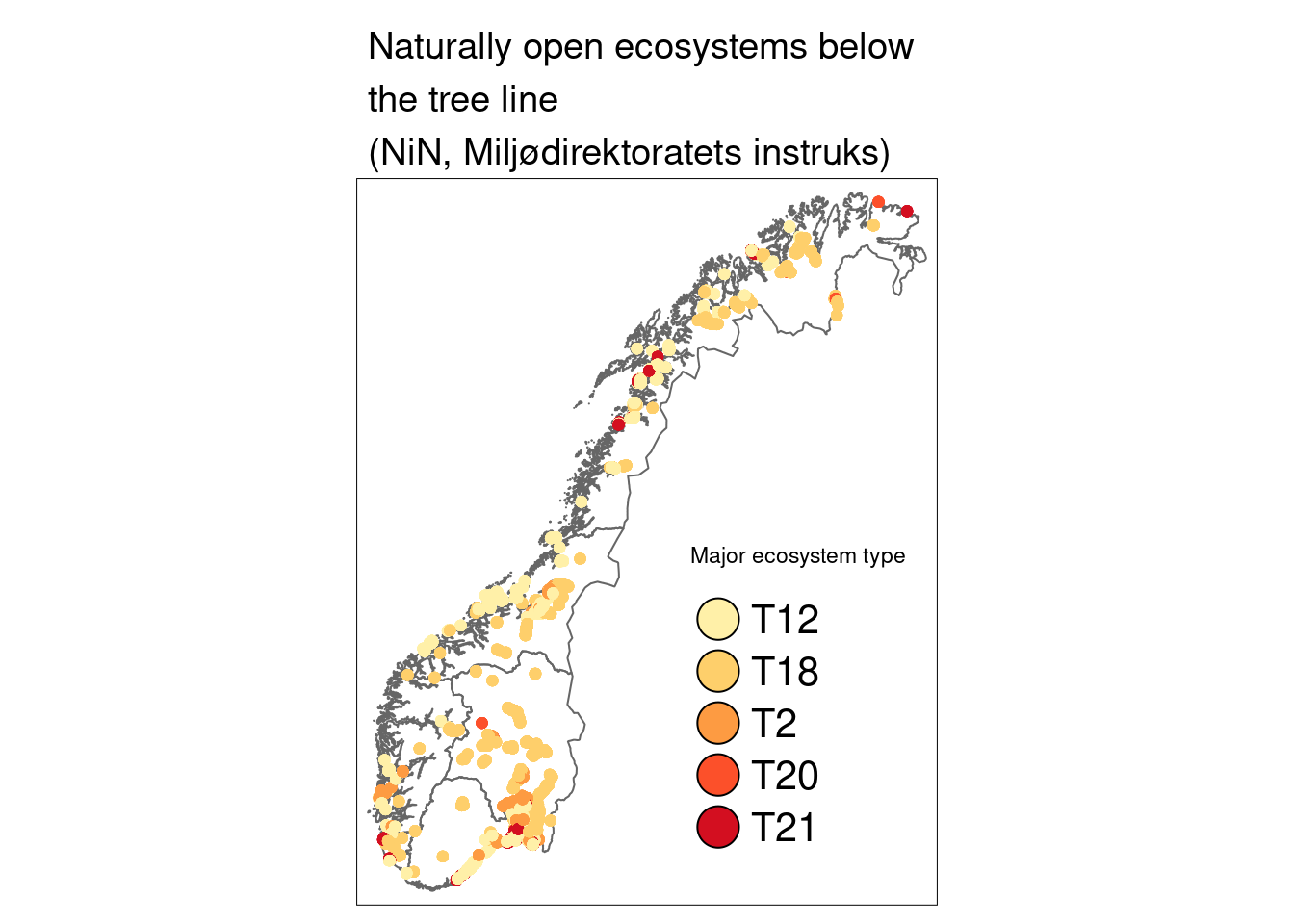
Figure 13.1: A map of Norway showing the location of the naturally open ecosystem sites. T12 = coastal meadows, T18 = flood plains, T2 = shallow soils, T20 = innfrysningsmark, T21 = sand dunes.
How are polygon sizes distributed?
summary(SentinelNDVI.natopen$area_meters)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 143.1 542.2 1192.8 4213.1 3267.2 243697.1
hist(SentinelNDVI.natopen$area_meters, xlim = c(0, 20000), breaks = 50000,xlab="Area",main="")
abline(v = 100, lty = 2)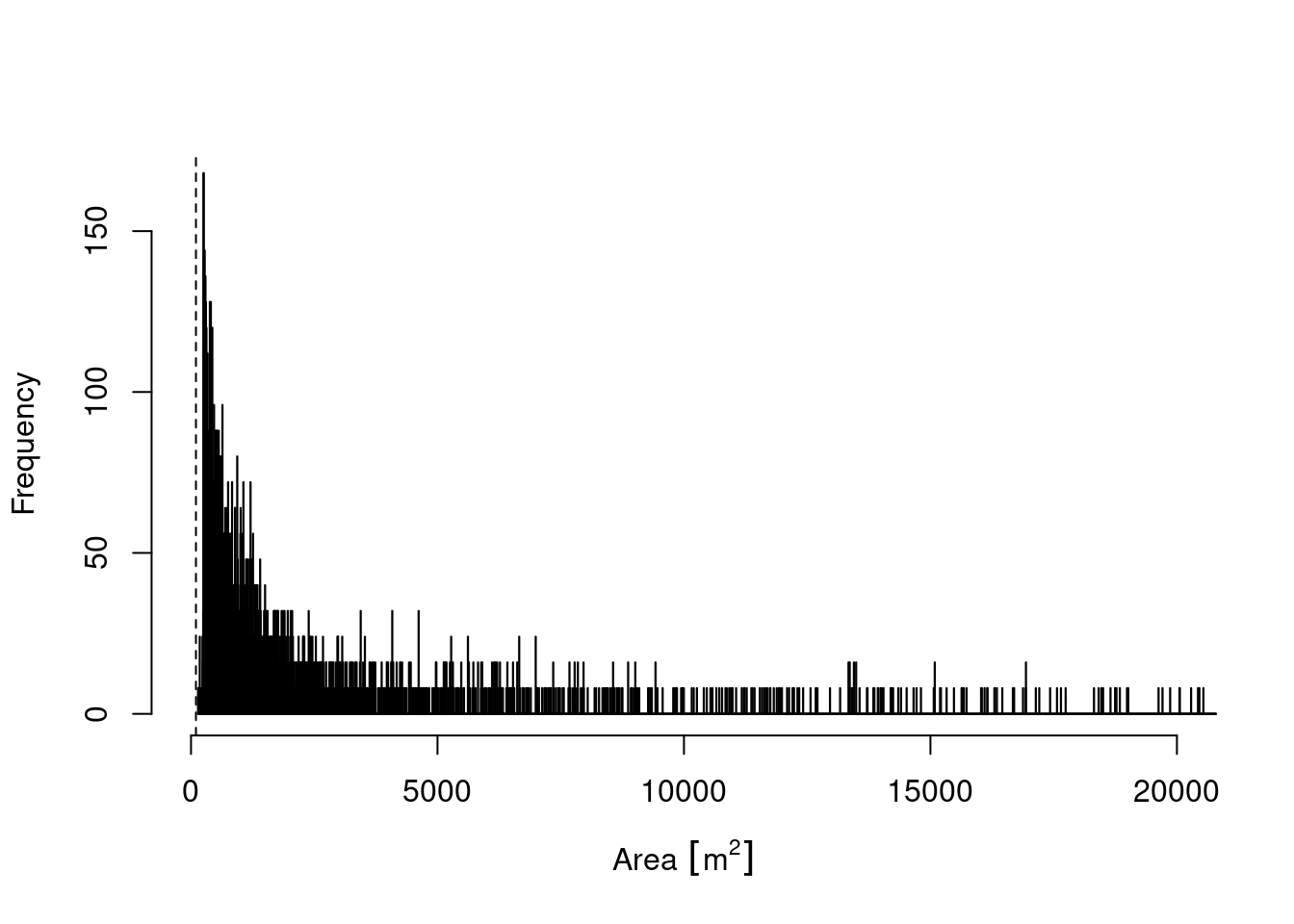
Figure 13.2: Histogram of naturally open ecosystem polygon sizes in Norway.
Natopen polygons stretch a large number of sizes from just above 100 sqm to almost 250 000 sqm. 75% of all polygons are below 4213 sqm. The dashed line indicates the minimum size of the Sentinel-2 pixels for NDVI, all NiN-polygons smaller than that have been removed form the data.
How does NDVI vary over the years?
SentinelNDVI.natopen %>%
filter(tilstand!="") %>%
ggplot(aes(x = year, y = mean)) +
geom_point() +
facet_grid(tilstand ~ hovedtype) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 12)) +
ggtitle("NDVI across years for different ecosystem types in all condition classes") +
labs(y = "NDVI values (Sentinel-2)", x = "Year")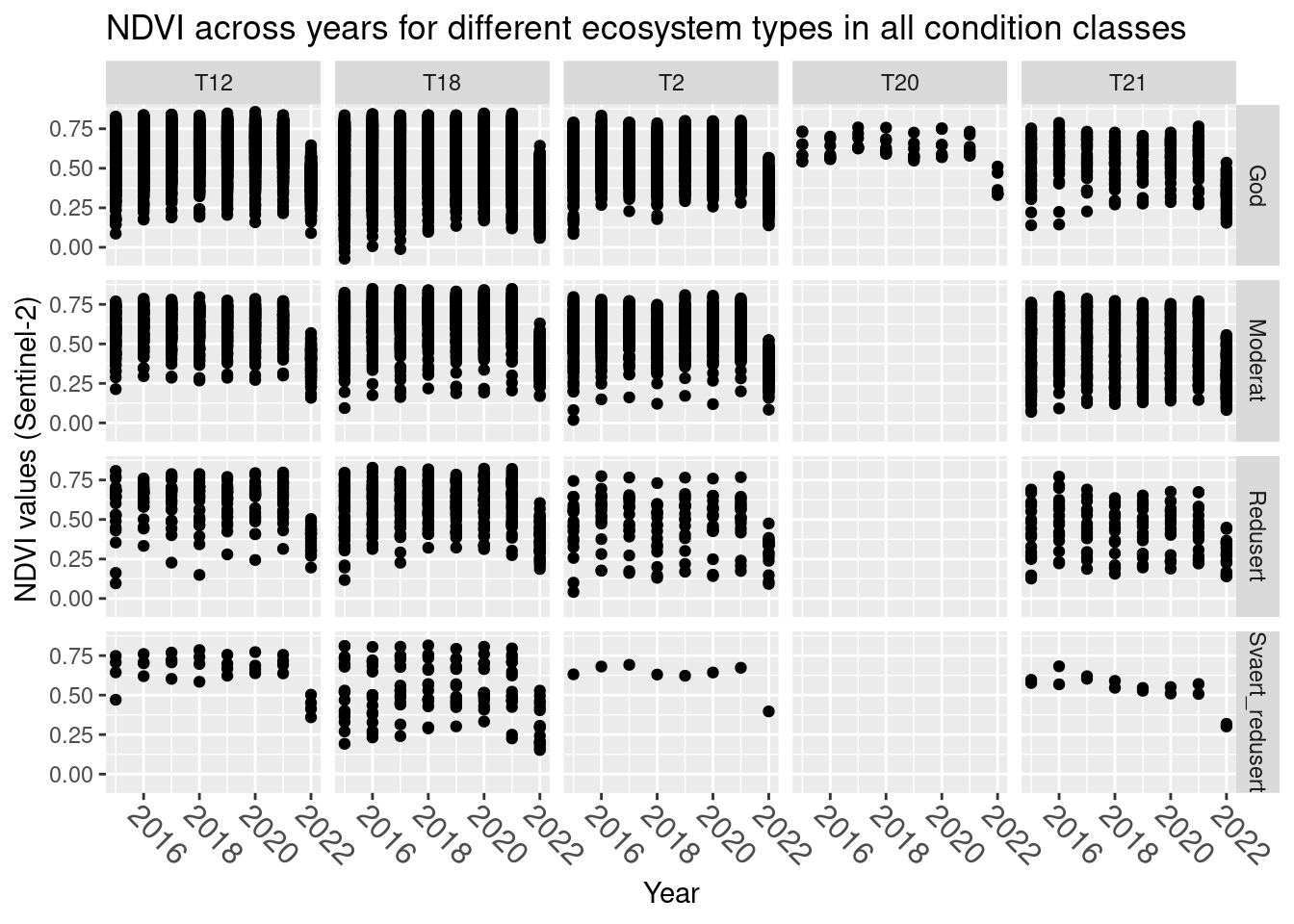
Figure 13.3: A figure showing NDVI values for naturally open ecosystem over time for six different main nature types in varying degrees of condition.
2022 stands out with the highest NDVI values missing. WE omit 2022 for this analysis
How do NDVI values vary between major and basic ecosystem types for sites in good condition? (using only NDVI data matching NiN-mapping years)
SentinelNDVI.natopen %>%
filter(tilstand == "God") %>%
filter(year == kartleggingsaar) %>%
ggplot(aes(x = hovedtype, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
ggtitle("NDVI for different ecosystem types in good condition") +
labs(y = "NDVI values (Sentinel-2)", x = "Major ecosystem type")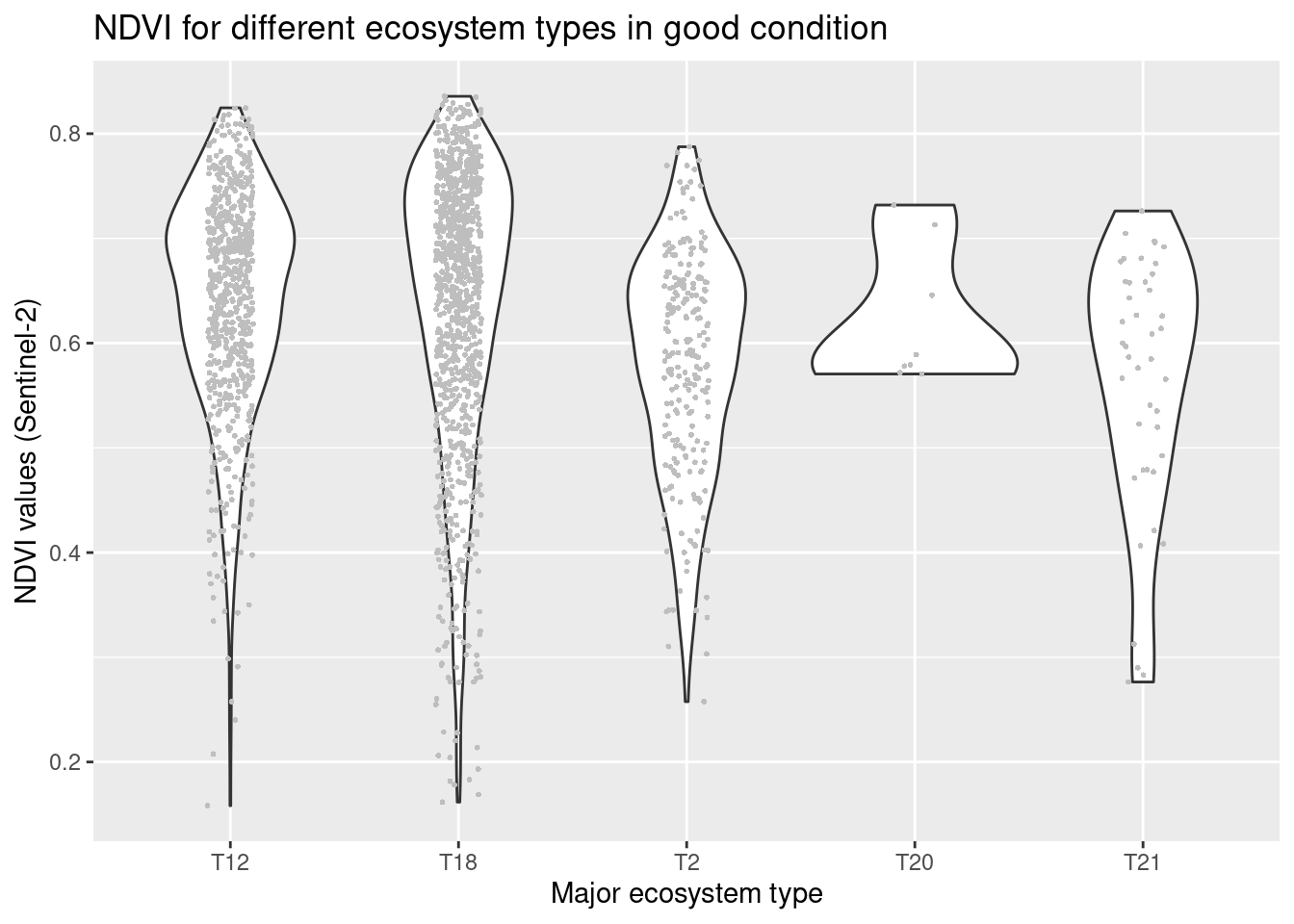
Figure 13.4: NDVI values in major natopen ecosystem types in good condition.
SentinelNDVI.natopen$subtype <- factor(SentinelNDVI.natopen$subtype, levels = c("C1", "C2", "C3", "C4", "C5", "C6", "C7", "C8", "E1"))
SentinelNDVI.natopen %>%
filter(tilstand == "God") %>%
filter(year == kartleggingsaar) %>%
ggplot(aes(x = subtype, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
facet_wrap(~hovedtype) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 12)) +
ggtitle("NDVI for different ecosystem sub-types in good condition") +
labs(y = "NDVI values (Sentinel-2)", x = "Ecosystem sub-type")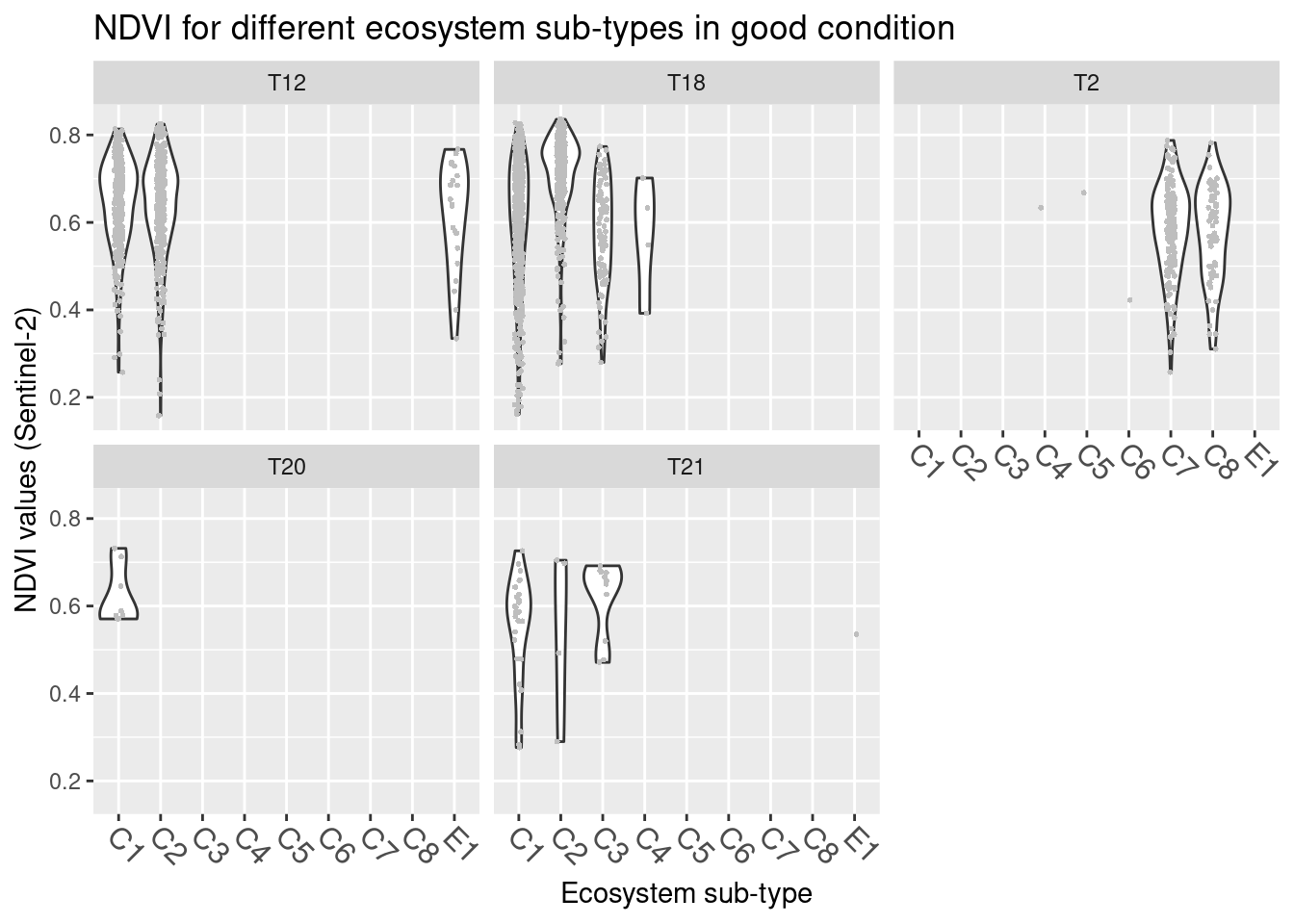
Figure 13.5: NDVI values in basic natopen ecosystem types in good condition.
NDVI varies between major ecosystem types with the highest values in open flood plains (T18) and in natural coastal meadows (T12), followed by naturally open areas on shallow soils (T2) and vegetated sand dunes (T21). There’s very little data on T20 (isinnfrysingsmark) and all mapped areas of that type are in good condition. Therefore we will omit this ecosystem type from the statistical analyses further below. The overlaps between the ecosystem types are considerable. With respect to basic ecosystem types within the major types, NDVI appears to cover very similar ranges across the subtypes, but sample size are also rather small. There is no obvious trend related to the structuring environmental gradients withing the major types, and also here the overlap is large.
How does NDVI vary across regions in natopens (major types) in good condition? (using only NDVI data matching NiN-mapping years)
SentinelNDVI.natopen %>%
filter(tilstand == "God") %>%
filter(year == kartleggingsaar) %>%
filter(!is.na(region)) %>%
ggplot(aes(x = region, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
facet_wrap(~hovedtype) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
ggtitle("NDVI for different ecosystems in good condition across regions") +
labs(y = "NDVI values (Sentinel-2)", x = "Region")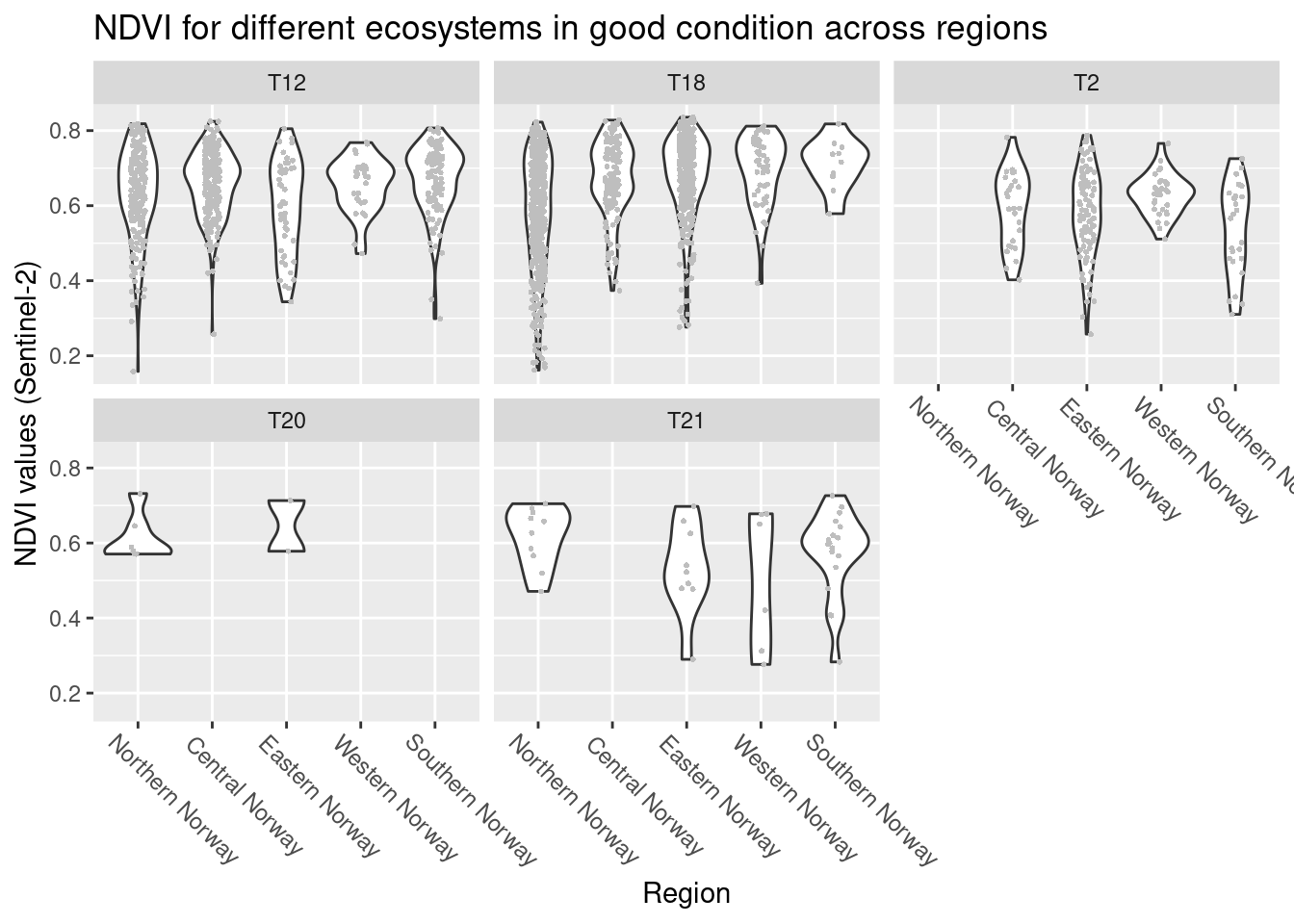
Figure 13.6: NDVI variation across regions in natopen ecosystems (major types) in good condition.
There is no obvious trends in geography.
How does NDVI vary across condition classes (for major types and NDVI data matching NiN-mapping years)?
SentinelNDVI.natopen %>%
filter(year == kartleggingsaar) %>%
filter(tilstand != "") %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
facet_wrap(~hovedtype) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2)) +
ggtitle("NDVI for different ecosystems in different condition classes") +
labs(y = "NDVI values (Sentinel-2)", x = "Condition")
Figure 13.7: NDVI values across natopen sites in different ecological condition.
The plots suggest a slight decrease in NDVI as condition deteriorates. Overlaps between condition classes are generally very large.
Which ecological relevant variable(s) is the condition measure in the NiN data related to?
nin.natopen2 %>%
filter(hovedtype == "T2") %>%
filter(NiN_variable_code %in% c("7FA", "7SE", "7TK", "1AG-B")) %>%
mutate(NiN_variable_des = recode(NiN_variable_code,
"7FA" = "Alien species",
"7SE" = "Wear/tear",
"7TK" = "Heavy vehicles",
"1AG-B" = "Shrub cover"
)) %>%
ggplot(aes(x = NiN_variable_value, y = tilstand_num)) +
geom_point(size = 2) +
geom_jitter(width = 0.25, height = 0.25) +
facet_wrap(~NiN_variable_des, ncol = 2) +
theme(legend.position = "none") +
ggtitle("Condition variables in open systems on shallow soils (T2)") +
labs(y = "Condition level (0-3='good' to 'very reduced')", x = "Condition variable score")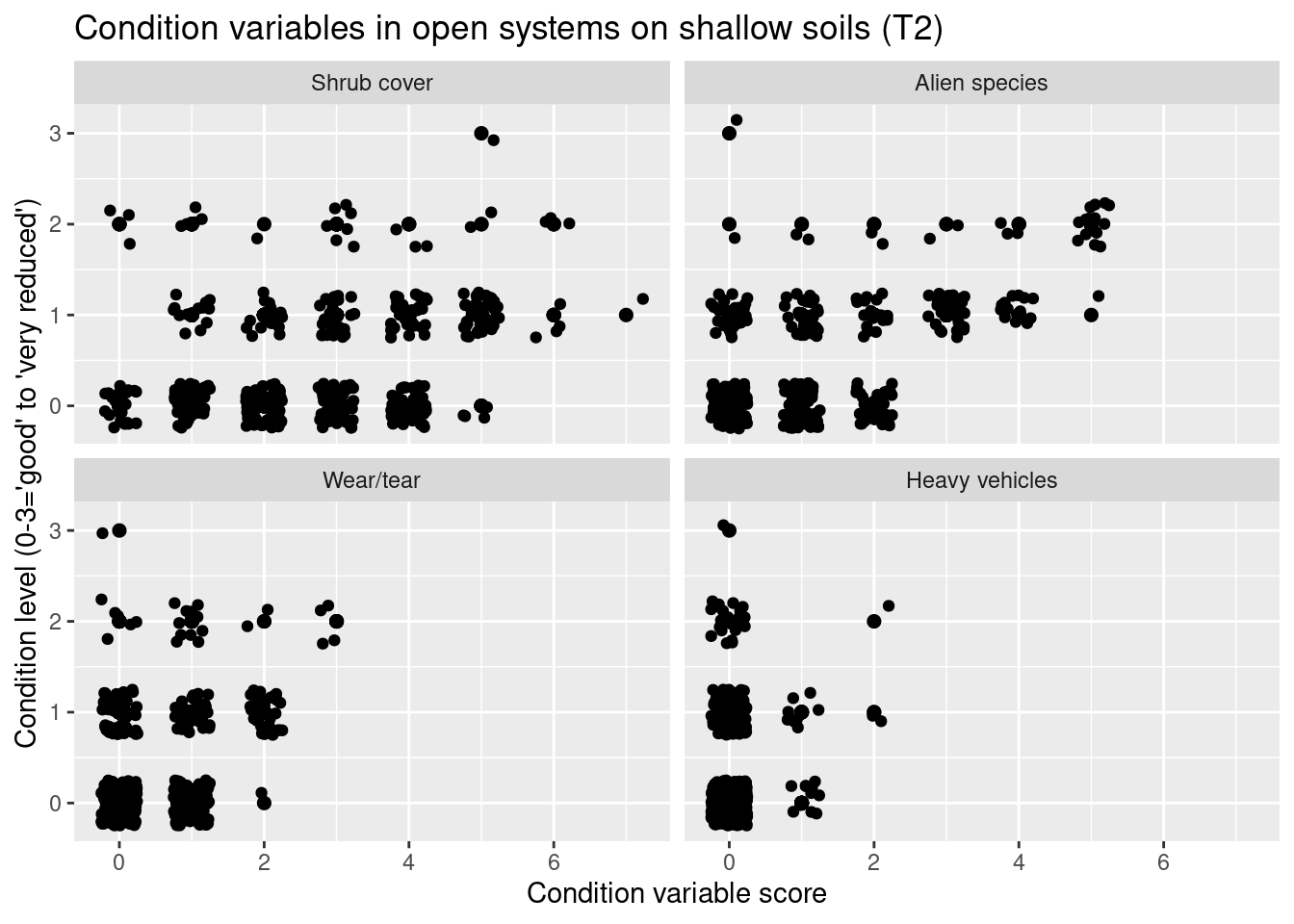
nin.natopen2 %>%
filter(hovedtype == "T12") %>%
filter(NiN_variable_code %in% c("7FA", "7SE", "7TK")) %>%
mutate(NiN_variable_des = recode(NiN_variable_code,
"7FA" = "Alien species",
"7SE" = "Wear/tear",
"7TK" = "Heavy vehicles"
)) %>%
ggplot(aes(x = NiN_variable_value, y = tilstand_num)) +
geom_point(size = 2) +
geom_jitter(width = 0.25, height = 0.25) +
facet_wrap(~NiN_variable_des, ncol = 2) +
theme(legend.position = "none") +
ggtitle("Condition variables in natural coastal meadows (T12)") +
labs(y = "Condition level (0-3='good' to 'very reduced')", x = "Condition variable score")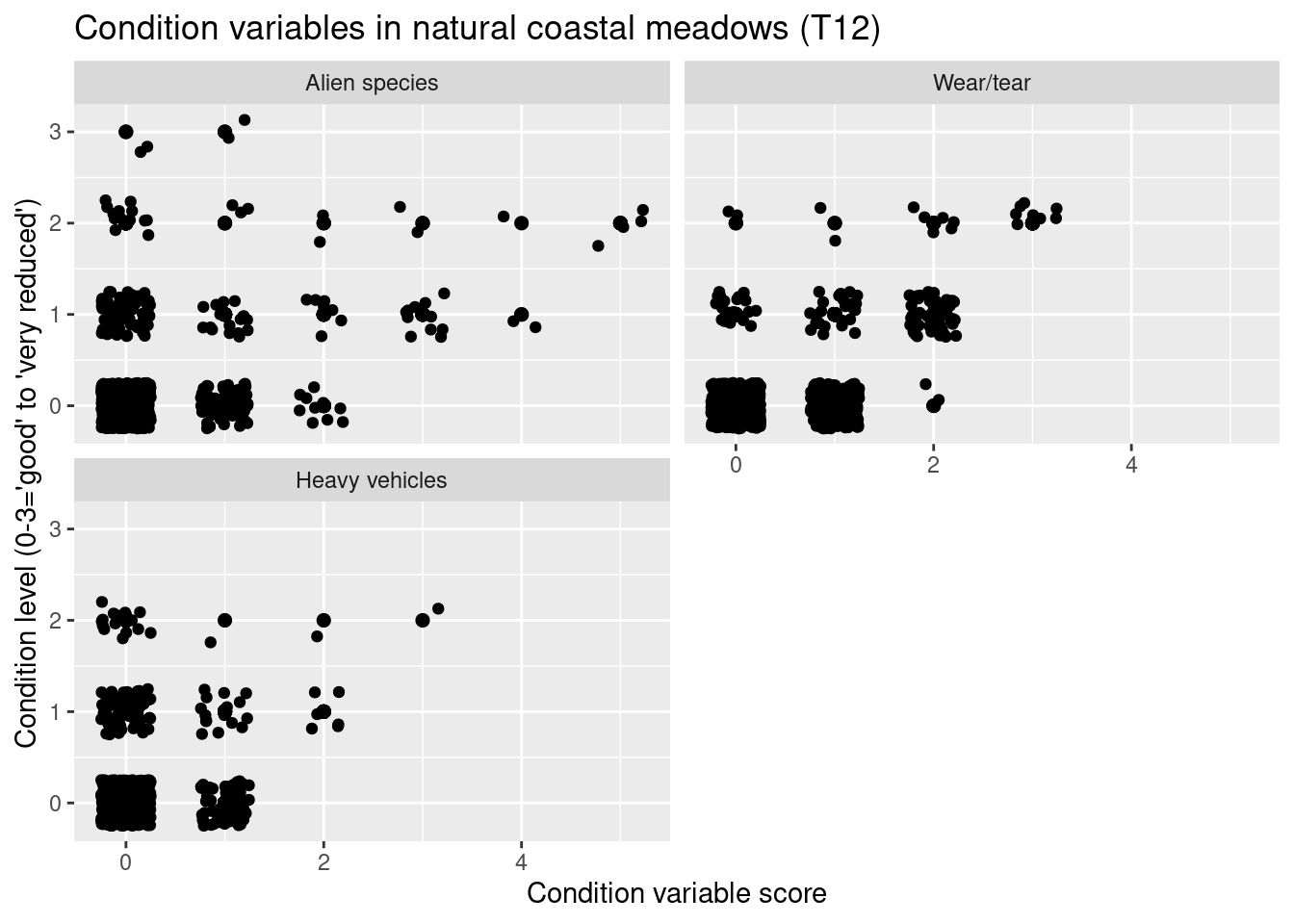
nin.natopen2 %>%
filter(hovedtype == "T18") %>%
filter(NiN_variable_code %in% c("7FA", "7JB-BT", "7SE", "7VR-RI")) %>%
mutate(NiN_variable_des = recode(NiN_variable_code,
"7FA" = "Alien species",
"7JB-BT" = "Grazing pressure",
"7SE" = "Wear/tear",
"7VR-RI" = "Water regulation"
)) %>%
ggplot(aes(x = NiN_variable_value, y = tilstand_num)) +
geom_point(size = 2) +
geom_jitter(width = 0.25, height = 0.25) +
facet_wrap(~NiN_variable_des, ncol = 2) +
theme(legend.position = "none") +
ggtitle("Condition variables in flood plains (T18)") +
labs(y = "Condition level (0-3='good' to 'very reduced')", x = "Condition variable score")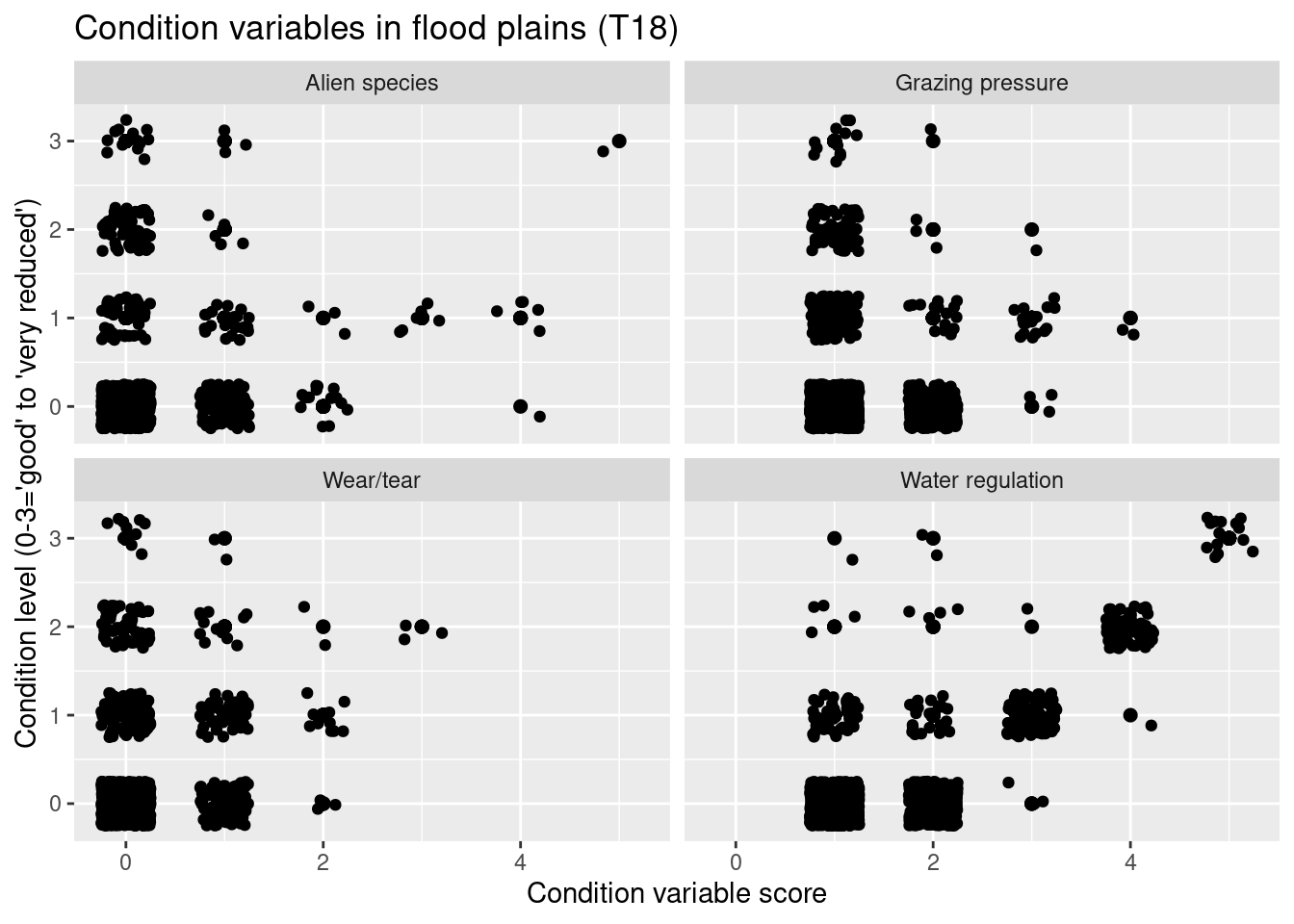
nin.natopen2 %>%
filter(hovedtype %in% c("T21")) %>%
filter(NiN_variable_code %in% c("7FA", "7JB-BT", "7SE", "7TK", "7JB-GJ")) %>%
mutate(NiN_variable_des = recode(NiN_variable_code,
"7FA" = "Alien species",
"7JB-BT" = "Grazing pressure",
"7SE" = "Wear/tear",
"7TK" = "Heavy vehicles",
"7JB-GJ" = "Fertilization"
)) %>%
ggplot(aes(x = NiN_variable_value, y = tilstand_num)) +
geom_point(size = 2) +
geom_jitter(width = 0.25, height = 0.25) +
facet_wrap(~NiN_variable_des, ncol = 2) +
theme(legend.position = "none") +
ggtitle("Condition variables in sand dunes (T21)") +
labs(y = "Condition level (0-3='good' to 'very reduced')", x = "Condition variable score")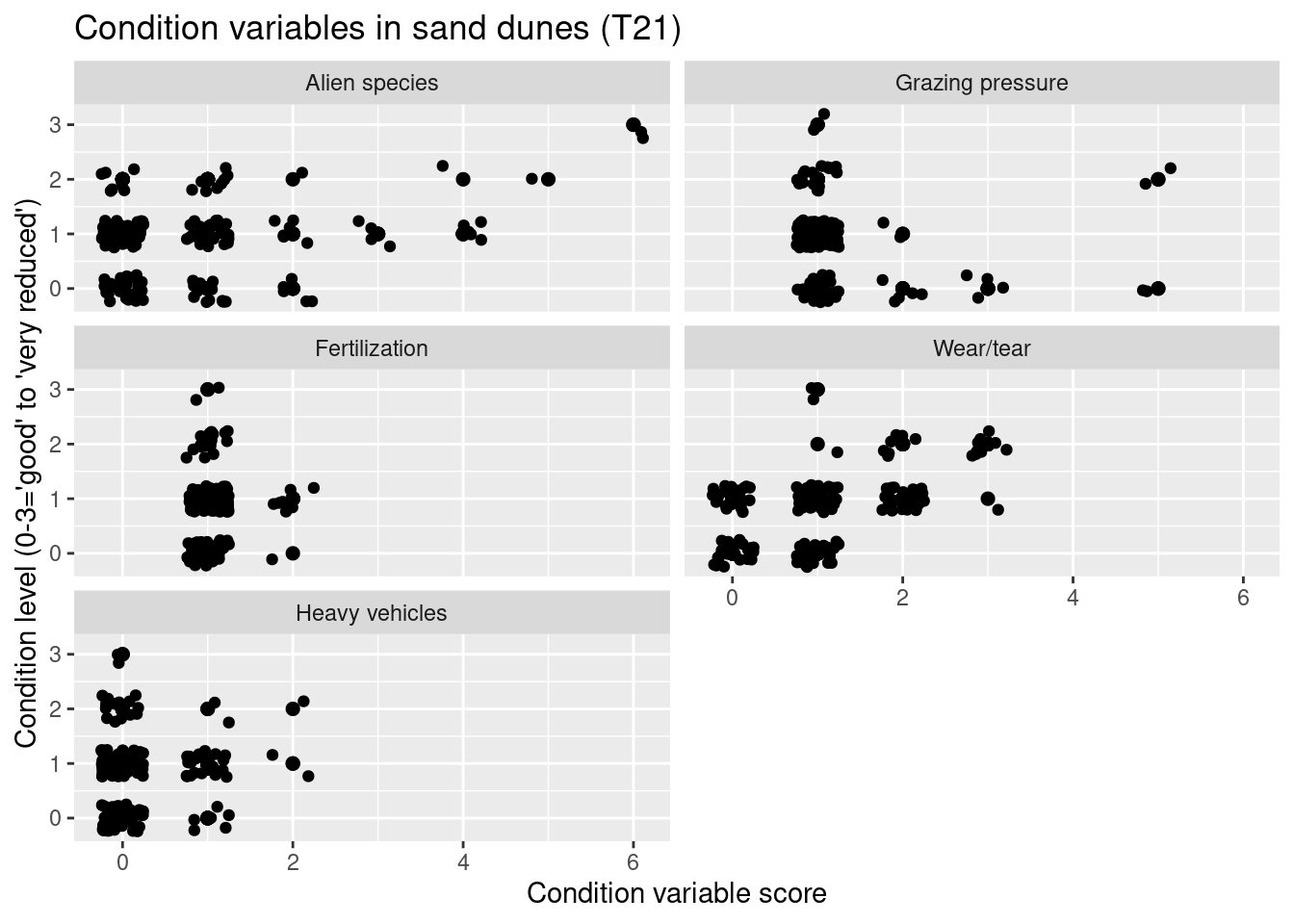
In these plots, the panels for the different major ecosystem types differ because Miljødirektoratets mapping manual (see reference list above) uses different variables in these major ecosystem types to define condition.
In open systems on shallow soils - T2 - reduced condition is mainly related to high levels of alien species, and also to damage from heavy vehicles. In the coastal meadows - T12 - reduced condition is related to high levels of alien species, but also to wear/tear and damage from heavy vehicles. I flood plains - T18 - reduced condition is mainly related to effects of water regulation. In sand dunes - T21 - reduced condition is mainly related to high levels of alien species and wear/tear. Wear/tear and damage related issues as well as water regulation might alter the amount of vegetation and thus the NDVI signal.
13.7.4 Regression analyses Sentinel-2, NDVI as a function of condition
We can investigate further how NDVI and condition are connected using regression analyses.
First, we take a look at how balanced the data are across major ecosystem types, regions and condition classes
# NDVI across hovedtyper, regions and condition classes (only for NDVI years data matching NiN-mapping years)
SentinelNDVI.natopen %>%
group_by(id, year) %>%
filter(year == kartleggingsaar) %>%
filter(tilstand != "") %>%
filter(!is.na(region)) %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey",) +
facet_grid(region ~ hovedtype) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
labs(y = "NDVI values (Sentinel-2)", x = "Condition")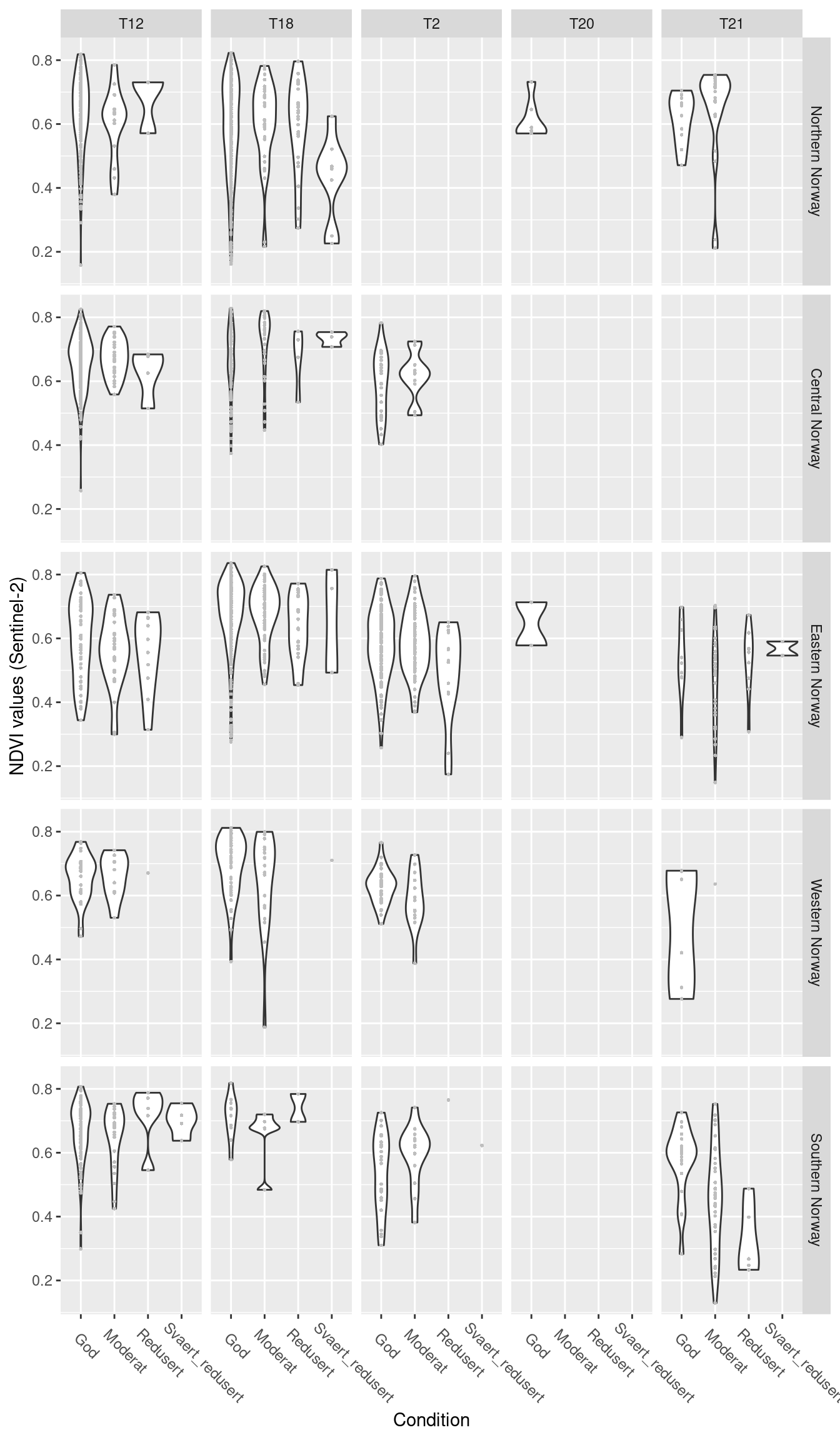
Figure 13.8: NDVI values across a condition gradient, faceted by natopen ecosystem types in five regions in Norway.
T20 is has only very few data and is present in only 1 condition class and 2 regions, we omit it. Northern Norway does not have any T2 occurrences, central Norway doesn’t have any T21 occurrences, we won’t be able to model these types across all regions.
NDVI data are bounded between -1 and 1, and thus require modelling with an appropriate method that can handle bounded data. We can transform the variable to be bounded between 0 and 1 and use beta-regression models:
SentinelNDVI.natopen$mean_beta <- (SentinelNDVI.natopen$mean + 1) / 2
# NDVI data from the year of NiN-mapping (and thus with condition assessment) to train the condition models
# we drop T41 for the analysis as it lacks data for most combinations of condition and region, and thus would cause convergence issues
SentinelNDVI.natopen.train <- SentinelNDVI.natopen %>%
filter(year == kartleggingsaar) %>%
filter(hovedtype != "T20")
# check if there's any 0s or 1s (which beta cannot handle)
# summary(SentinelNDVI.natopen.train$mean_beta) # ok
# We run a stepwise-function on the full model including condition, ecosystem type, and region to find the most parsimonious model
# we exclude Northern Norway and T21 for this first exploratory model
model.natopen.cond.Sent <- betareg(mean_beta ~ tilstand_num * region * hovedtype, data = SentinelNDVI.natopen.train[SentinelNDVI.natopen.train$region != "Northern Norway" & SentinelNDVI.natopen.train$hovedtype != "T21", ])
model.natopen.cond.Sent <- StepBeta(model.natopen.cond.Sent)
#> [1] "100 % of the process"
summary(model.natopen.cond.Sent)
#>
#> Call:
#> c("betareg(formula = mean_beta ~ hovedtype + region + tilstand_num + region:hovedtype + tilstand_num:region data = [ )",
#> "betareg(formula = mean_beta ~ hovedtype + region + tilstand_num + region:hovedtype + tilstand_num:region data = SentinelNDVI.natopen.train )",
#> "betareg(formula = mean_beta ~ hovedtype + region + tilstand_num + region:hovedtype + tilstand_num:region data = SentinelNDVI.natopen.train$region != \"Northern Norway\" & SentinelNDVI.natopen.train$hovedtype != \"T21\" )",
#> "betareg(formula = mean_beta ~ hovedtype + region + tilstand_num + region:hovedtype + tilstand_num:region data = )"
#> )
#>
#> Standardized weighted residuals 2:
#> Min 1Q Median 3Q Max
#> -3.6826 -0.6398 0.0606 0.6959 2.6998
#>
#> Coefficients (mean model with logit link):
#> Estimate Std. Error
#> (Intercept) 1.56165 0.02045
#> hovedtypeT18 0.08094 0.03369
#> hovedtypeT2 -0.20463 0.05545
#> regionEastern Norway -0.20104 0.04100
#> regionWestern Norway 0.01462 0.05877
#> regionSouthern Norway 0.02528 0.03680
#> tilstand_num 0.06167 0.03310
#> hovedtypeT18:regionEastern Norway 0.21499 0.05065
#> hovedtypeT2:regionEastern Norway 0.19473 0.06850
#> hovedtypeT18:regionWestern Norway 0.02995 0.07515
#> hovedtypeT2:regionWestern Norway 0.06735 0.09042
#> hovedtypeT18:regionSouthern Norway 0.01409 0.09531
#> hovedtypeT2:regionSouthern Norway -0.12881 0.07859
#> regionEastern Norway:tilstand_num -0.12009 0.03835
#> regionWestern Norway:tilstand_num -0.12763 0.06146
#> regionSouthern Norway:tilstand_num -0.01373 0.04844
#> z value Pr(>|z|)
#> (Intercept) 76.366 < 2e-16 ***
#> hovedtypeT18 2.403 0.016283 *
#> hovedtypeT2 -3.691 0.000224 ***
#> regionEastern Norway -4.904 9.41e-07 ***
#> regionWestern Norway 0.249 0.803577
#> regionSouthern Norway 0.687 0.492069
#> tilstand_num 1.863 0.062447 .
#> hovedtypeT18:regionEastern Norway 4.245 2.19e-05 ***
#> hovedtypeT2:regionEastern Norway 2.843 0.004471 **
#> hovedtypeT18:regionWestern Norway 0.399 0.690251
#> hovedtypeT2:regionWestern Norway 0.745 0.456355
#> hovedtypeT18:regionSouthern Norway 0.148 0.882495
#> hovedtypeT2:regionSouthern Norway -1.639 0.101211
#> regionEastern Norway:tilstand_num -3.131 0.001740 **
#> regionWestern Norway:tilstand_num -2.077 0.037827 *
#> regionSouthern Norway:tilstand_num -0.283 0.776822
#>
#> Phi coefficients (precision model with identity link):
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 60.966 2.176 28.02 <2e-16 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Type of estimator: ML (maximum likelihood)
#> Log-likelihood: 2540 on 17 Df
#> Pseudo R-squared: 0.1497
#> Number of iterations: 24 (BFGS) + 1 (Fisher scoring)NDVI values do vary between:
- Regions
- Ecosystem types
- Condition classes
It is evident that there are differences between regions. But since we are not interested in the statistics for region differences, we run separate models for every region for ease of interpretation.
model.natopen.cond.Sent.N <- betareg(mean_beta ~ tilstand_num * hovedtype, data = SentinelNDVI.natopen.train[SentinelNDVI.natopen.train$region == "Northern Norway", ])
model.natopen.cond.Sent.C <- betareg(mean_beta ~ tilstand_num * hovedtype, data = SentinelNDVI.natopen.train[SentinelNDVI.natopen.train$region == "Central Norway", ])
model.natopen.cond.Sent.W <- betareg(mean_beta ~ tilstand_num * hovedtype, data = SentinelNDVI.natopen.train[SentinelNDVI.natopen.train$region == "Western Norway", ])
model.natopen.cond.Sent.E <- betareg(mean_beta ~ tilstand_num * hovedtype, data = SentinelNDVI.natopen.train[SentinelNDVI.natopen.train$region == "Eastern Norway", ])
model.natopen.cond.Sent.S <- betareg(mean_beta ~ tilstand_num * hovedtype, data = SentinelNDVI.natopen.train[SentinelNDVI.natopen.train$region == "Southern Norway", ])Northern Norway
SentinelNDVI.natopen.train %>%
filter(region == "Northern Norway") %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
ggtitle("Northern Norway") +
labs(y = "NDVI values (Sentinel-2)", x = "Condition") +
facet_wrap(~hovedtype)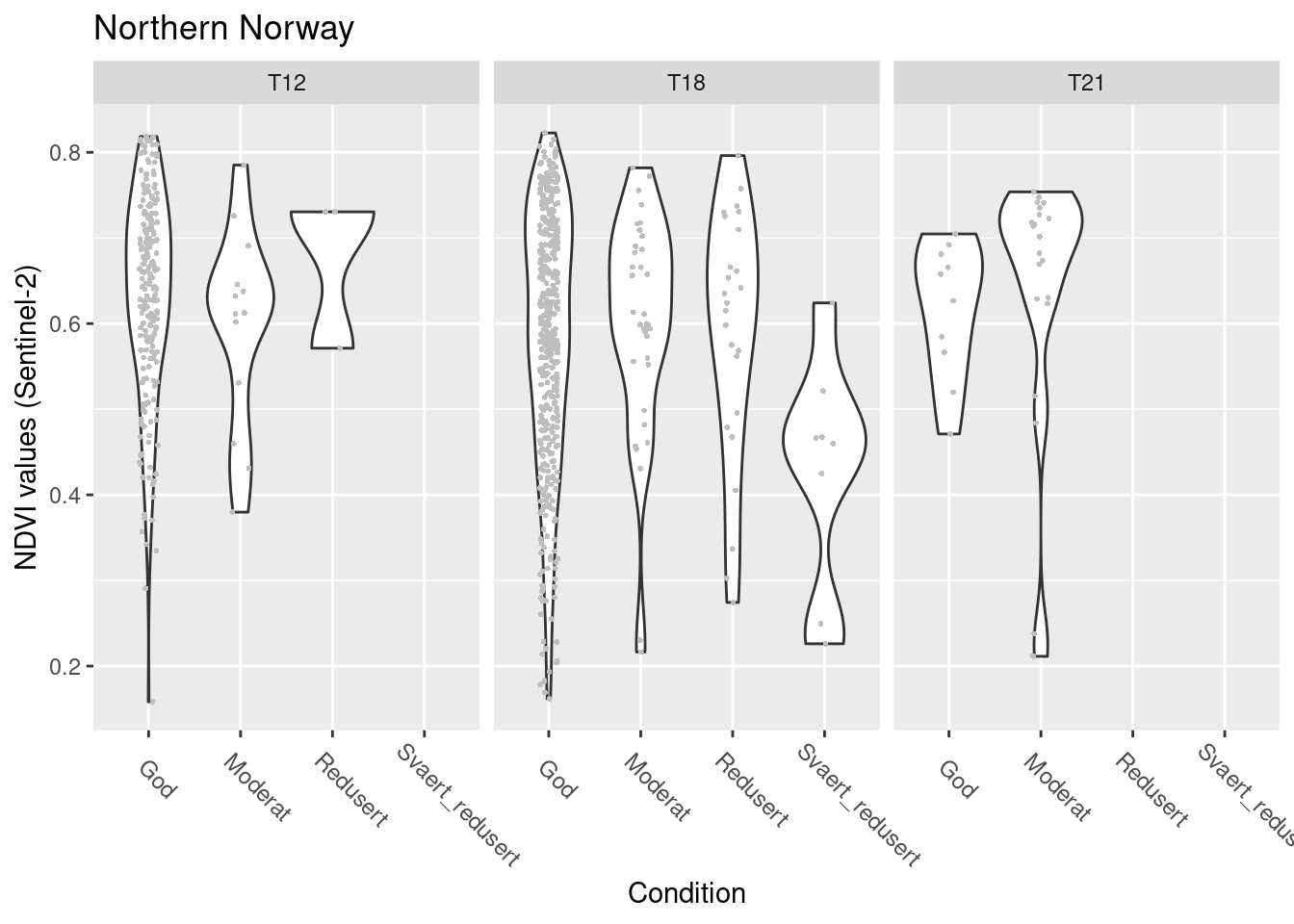
Figure 13.9: NDVI against ecosystem condition for natopen ecosystems in Northern Norway.
summary(model.natopen.cond.Sent.N)$coefficients
#> $mean
#> Estimate Std. Error z value
#> (Intercept) 1.47874752 0.02922669 50.5957848
#> tilstand_num -0.03216827 0.08501593 -0.3783793
#> hovedtypeT18 -0.13351837 0.03491454 -3.8241485
#> hovedtypeT21 -0.07849672 0.13432610 -0.5843743
#> tilstand_num:hovedtypeT18 -0.01124750 0.08995815 -0.1250303
#> tilstand_num:hovedtypeT21 0.13265089 0.18190713 0.7292231
#> Pr(>|z|)
#> (Intercept) 0.0000000000
#> tilstand_num 0.7051488568
#> hovedtypeT18 0.0001312248
#> hovedtypeT21 0.5589685024
#> tilstand_num:hovedtypeT18 0.9004995550
#> tilstand_num:hovedtypeT21 0.4658651799
#>
#> $precision
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 34.3952 1.745776 19.70195 2.07453e-86Not much of a pattern in either model or figure.
Central Norway
SentinelNDVI.natopen.train %>%
filter(region == "Central Norway") %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
ggtitle("Central Norway") +
labs(y = "NDVI values (Sentinel-2)", x = "Condition") + facet_wrap(~hovedtype) +
facet_wrap(~hovedtype)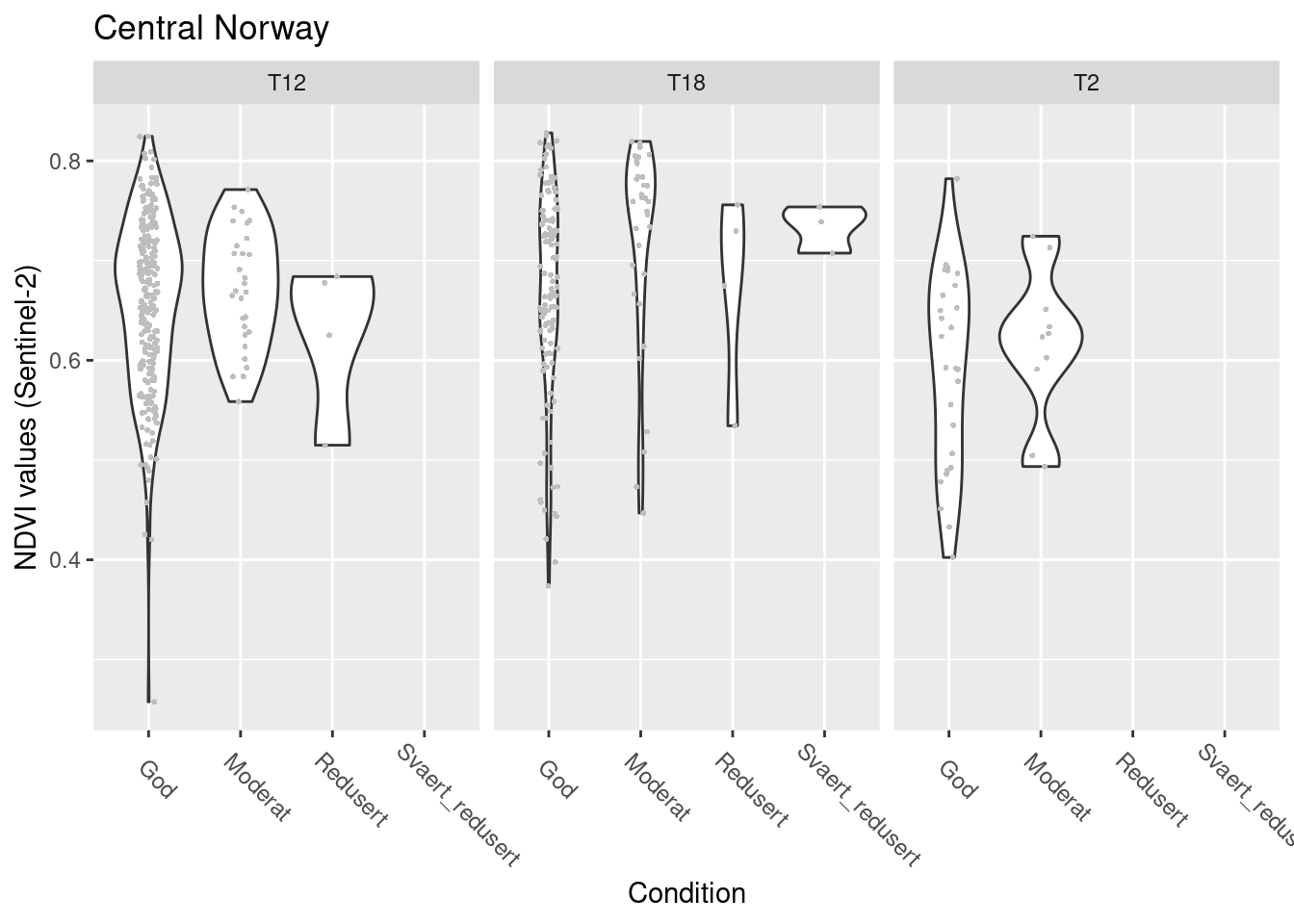
Figure 13.10: NDVI against ecosystem condition for natopen ecosystems in Central Norway.
summary(model.natopen.cond.Sent.C)$coefficients
#> $mean
#> Estimate Std. Error
#> (Intercept) 1.5753723757 0.01967735
#> tilstand_num -0.0005827379 0.04854023
#> hovedtypeT18 0.0605336826 0.03362481
#> hovedtypeT2 -0.2151633049 0.05881656
#> tilstand_num:hovedtypeT18 0.1074821469 0.06462158
#> tilstand_num:hovedtypeT2 0.0677333044 0.11859900
#> z value Pr(>|z|)
#> (Intercept) 80.06020546 0.0000000000
#> tilstand_num -0.01200526 0.9904214210
#> hovedtypeT18 1.80026841 0.0718182663
#> hovedtypeT2 -3.65820973 0.0002539832
#> tilstand_num:hovedtypeT18 1.66325467 0.0962614677
#> tilstand_num:hovedtypeT2 0.57111196 0.5679237536
#>
#> $precision
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 71.96558 4.636427 15.52178 2.471101e-54NDVI in good condition: T12/T18 > T2
No changes with condition.
Western Norway
SentinelNDVI.natopen.train %>%
filter(region == "Western Norway") %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
ggtitle("Western Norway") +
labs(y = "NDVI values (Sentinel-2)", x = "Condition") + facet_wrap(~hovedtype)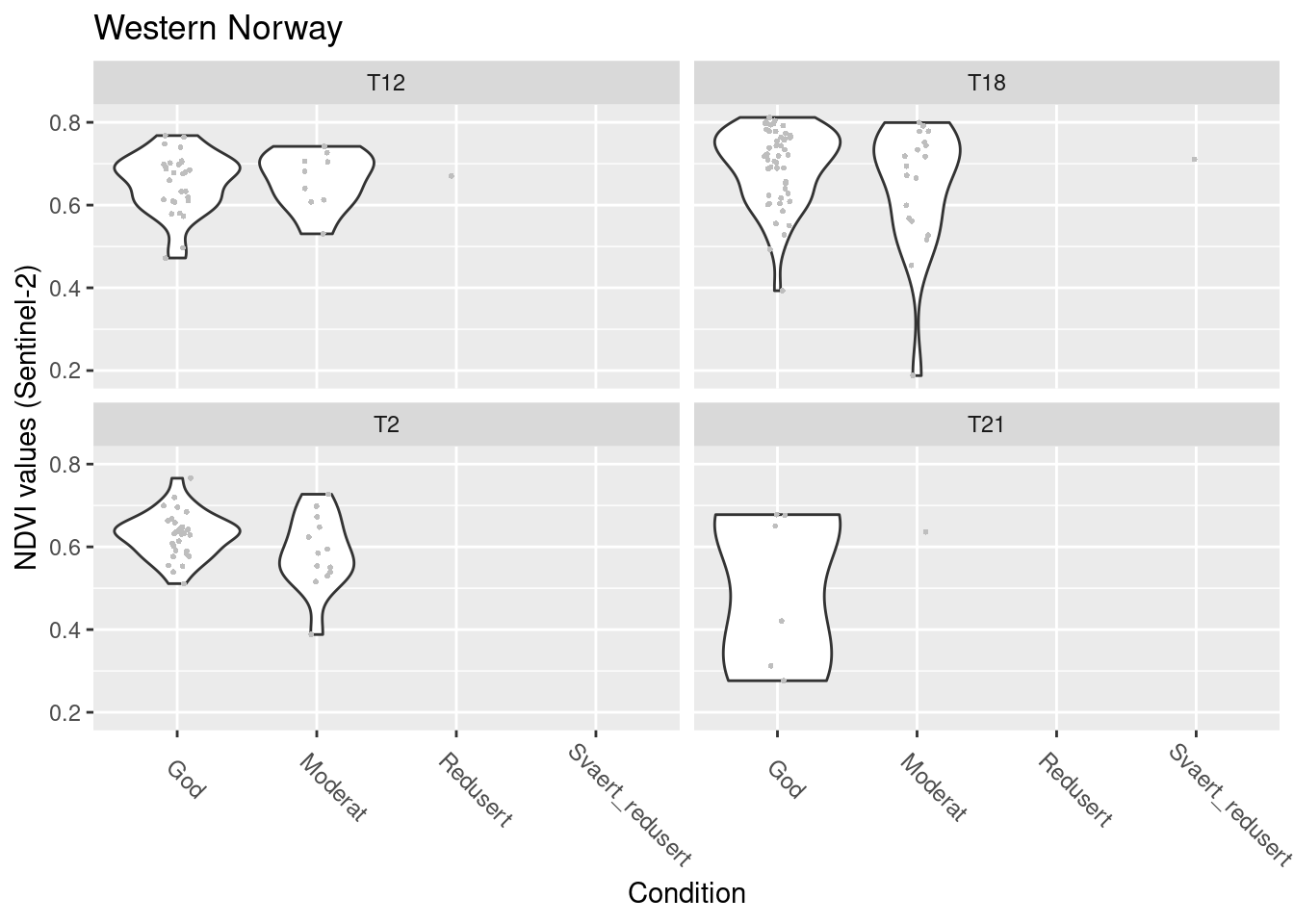
Figure 13.11: NDVI agains ecosystm condition for natopen ecosystems in W-Norway.
facet_wrap(~hovedtype)
#> <ggproto object: Class FacetWrap, Facet, gg>
#> compute_layout: function
#> draw_back: function
#> draw_front: function
#> draw_labels: function
#> draw_panels: function
#> finish_data: function
#> init_scales: function
#> map_data: function
#> params: list
#> setup_data: function
#> setup_params: function
#> shrink: TRUE
#> train_scales: function
#> vars: function
#> super: <ggproto object: Class FacetWrap, Facet, gg>
summary(model.natopen.cond.Sent.W)$coefficients
#> $mean
#> Estimate Std. Error z value
#> (Intercept) 1.55784725 0.05624467 27.6976845
#> tilstand_num 0.01620582 0.09773274 0.1658177
#> hovedtypeT18 0.14037004 0.07152772 1.9624564
#> hovedtypeT2 -0.09759038 0.07742434 -1.2604612
#> hovedtypeT21 -0.41797186 0.12442875 -3.3591260
#> tilstand_num:hovedtypeT18 -0.09643801 0.11864650 -0.8128179
#> tilstand_num:hovedtypeT2 -0.13632516 0.13682509 -0.9963462
#> tilstand_num:hovedtypeT21 0.31819062 0.33281378 0.9560620
#> Pr(>|z|)
#> (Intercept) 7.445255e-169
#> tilstand_num 8.683004e-01
#> hovedtypeT18 4.970937e-02
#> hovedtypeT2 2.075030e-01
#> hovedtypeT21 7.818942e-04
#> tilstand_num:hovedtypeT18 4.163225e-01
#> tilstand_num:hovedtypeT2 3.190820e-01
#> tilstand_num:hovedtypeT21 3.390409e-01
#>
#> $precision
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 71.86576 8.034702 8.944421 3.739035e-19NDVI in good condition: T18 marginally > T2/T12/T21
No changes with condition.
Eastern Norway
SentinelNDVI.natopen.train %>%
filter(region == "Eastern Norway") %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
ggtitle("Eastern Norway") +
labs(y = "NDVI values (Sentinel-2)", x = "Condition") + facet_wrap(~hovedtype)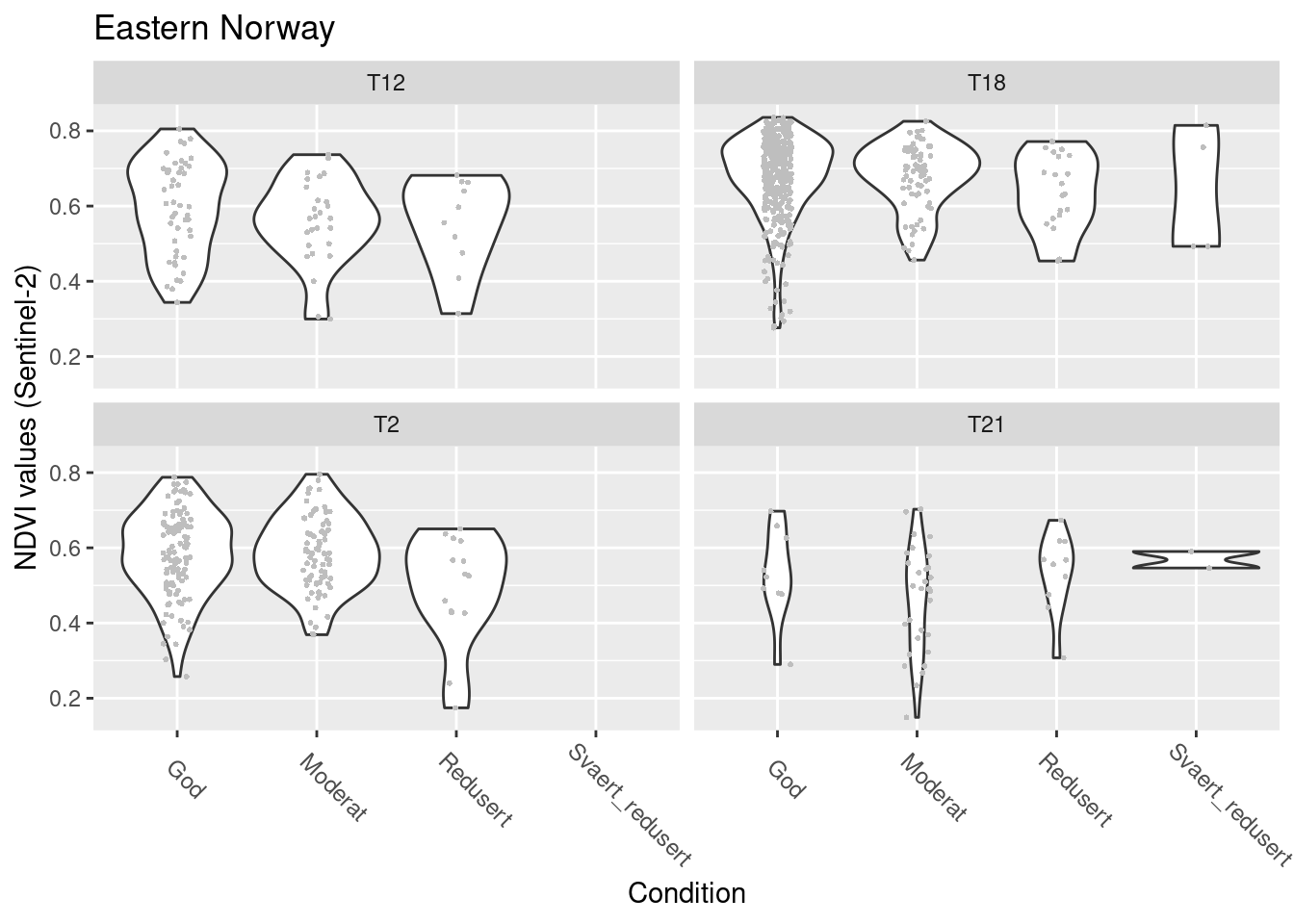
Figure 13.12: NDVI against ecosystem condition for natopen ecosystems in E-Norway.
facet_wrap(~hovedtype)
#> <ggproto object: Class FacetWrap, Facet, gg>
#> compute_layout: function
#> draw_back: function
#> draw_front: function
#> draw_labels: function
#> draw_panels: function
#> finish_data: function
#> init_scales: function
#> map_data: function
#> params: list
#> setup_data: function
#> setup_params: function
#> shrink: TRUE
#> train_scales: function
#> vars: function
#> super: <ggproto object: Class FacetWrap, Facet, gg>
summary(model.natopen.cond.Sent.E)$coefficients
#> $mean
#> Estimate Std. Error z value
#> (Intercept) 1.36897615 0.04740322 28.8793926
#> tilstand_num -0.08204417 0.05185250 -1.5822606
#> hovedtypeT18 0.27714819 0.05109404 5.4242763
#> hovedtypeT2 -0.02080965 0.05674090 -0.3667487
#> hovedtypeT21 -0.32041847 0.09309699 -3.4417704
#> tilstand_num:hovedtypeT18 0.03452959 0.05938858 0.5814179
#> tilstand_num:hovedtypeT2 0.01880438 0.06404575 0.2936086
#> tilstand_num:hovedtypeT21 0.11181593 0.08031978 1.3921343
#> Pr(>|z|)
#> (Intercept) 2.166902e-183
#> tilstand_num 1.135901e-01
#> hovedtypeT18 5.818981e-08
#> hovedtypeT2 7.138065e-01
#> hovedtypeT21 5.779205e-04
#> tilstand_num:hovedtypeT18 5.609588e-01
#> tilstand_num:hovedtypeT2 7.690570e-01
#> tilstand_num:hovedtypeT21 1.638817e-01
#>
#> $precision
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 51.59429 2.595269 19.88013 6.047901e-88NDVI in good condition: T18 > T2/T12 > T21
No changes with condition.
Southern Norway
SentinelNDVI.natopen.train %>%
filter(region == "Southern Norway") %>%
ggplot(aes(x = tilstand, y = mean)) +
geom_violin() +
geom_point(size = 0.7, shape = 16, color = "grey", position = position_jitter(.1) ) +
theme(axis.text.x = element_text(angle = -45, vjust = 0.5, hjust = 0.2, size = 9)) +
ggtitle("Southern Norway") +
labs(y = "NDVI values (Sentinel-2)", x = "Condition") + facet_wrap(~hovedtype)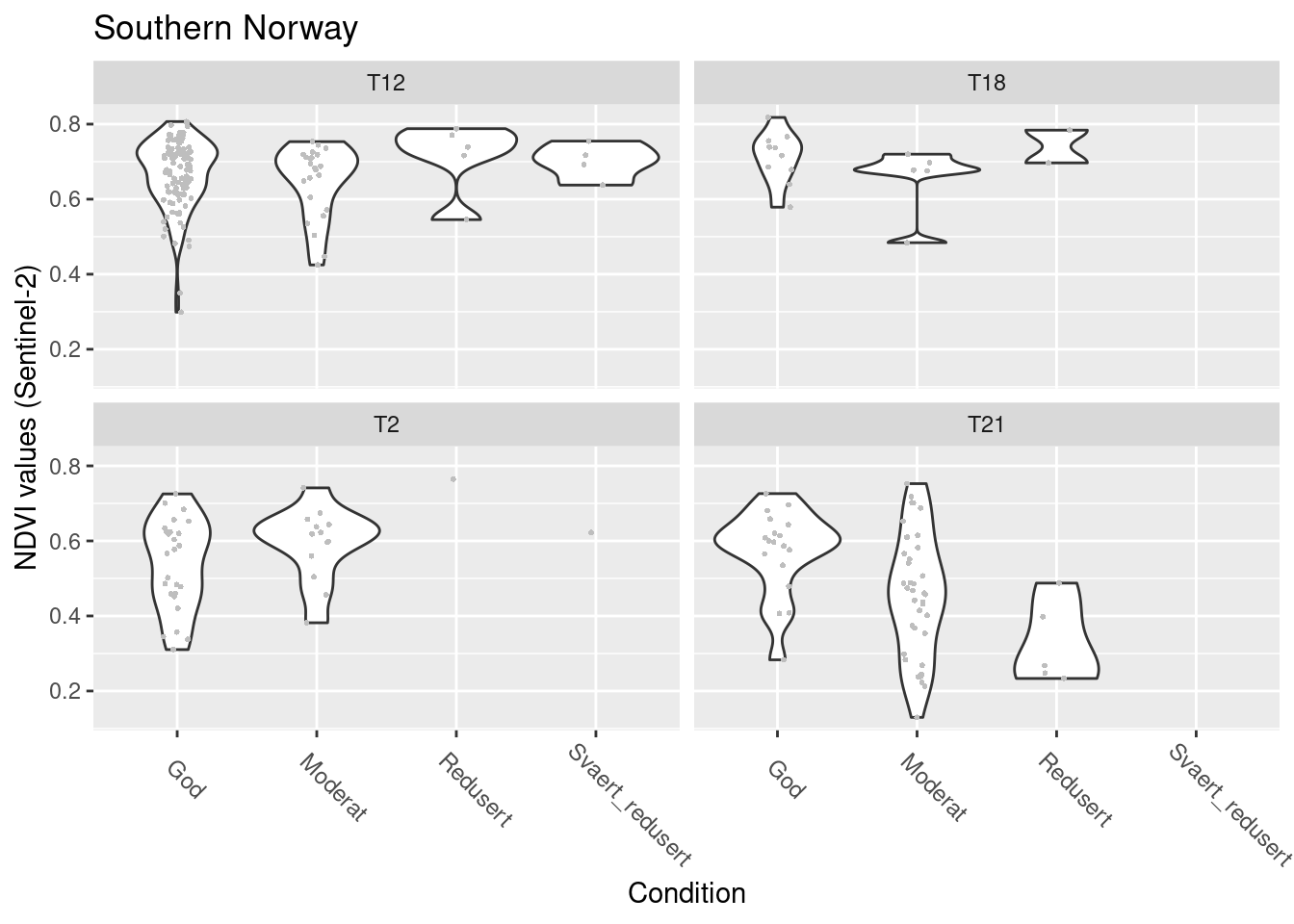
Figure 13.13: NDVI against ecosystem condition for natopen ecosystems in S-Norway.
facet_wrap(~hovedtype)
#> <ggproto object: Class FacetWrap, Facet, gg>
#> compute_layout: function
#> draw_back: function
#> draw_front: function
#> draw_labels: function
#> draw_panels: function
#> finish_data: function
#> init_scales: function
#> map_data: function
#> params: list
#> setup_data: function
#> setup_params: function
#> shrink: TRUE
#> train_scales: function
#> vars: function
#> super: <ggproto object: Class FacetWrap, Facet, gg>
summary(model.natopen.cond.Sent.S)$coefficients
#> $mean
#> Estimate Std. Error z value
#> (Intercept) 1.59377861 0.03253414 48.9878778
#> tilstand_num 0.01976630 0.04323083 0.4572271
#> hovedtypeT18 0.12214718 0.11316875 1.0793366
#> hovedtypeT2 -0.38939570 0.06627230 -5.8756928
#> hovedtypeT21 -0.28978244 0.07442588 -3.8935708
#> tilstand_num:hovedtypeT18 -0.04226168 0.13042010 -0.3240427
#> tilstand_num:hovedtypeT2 0.13978160 0.08861534 1.5773973
#> tilstand_num:hovedtypeT21 -0.32443033 0.07911115 -4.1009431
#> Pr(>|z|)
#> (Intercept) 0.000000e+00
#> tilstand_num 6.475079e-01
#> hovedtypeT18 2.804377e-01
#> hovedtypeT2 4.210787e-09
#> hovedtypeT21 9.877934e-05
#> tilstand_num:hovedtypeT18 7.459057e-01
#> tilstand_num:hovedtypeT2 1.147041e-01
#> tilstand_num:hovedtypeT21 4.114697e-05
#>
#> $precision
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 58.05791 5.108533 11.36489 6.254309e-30NDVI in good condition: T12/T18 > T2/T21
Reduced NDVI with reduced condition in sand dune vegetation types in Southern Norway. Otherwise no changes with condition.
Overall take home messages:
In naturally open ecosystems below the tree line, NDVI seems largely independent of ecosystem condition. This is probably because many of the regarding ecosystems are structured by natural disturbances anyways. The only system showing a clear and convincing trend is the sand dunes in Southern Norway with a reduction in NDVI as condition deteriorates (due to Wear/tear and alien species).
13.7.5 NDVI across time - Sentinel, MODIS & LandSat
As a last step, we can investigate how NDVI has changed over time. For this we include data from both MODIS and Landsat in addition to Sentinel-2.
First, there’s again some data handling to do. We merge the Sentinel, MODIS, and Landsat data to show the full picture across time. Then we model the time series for each Satellite separately.
## data handling for time series analysis
# Sentinel time series checked in exploratory analysis script
# checking time series for MODIS
# ModisNDVI.natopen %>%
# group_by(id, year) %>%
# filter(mean == max(mean, na.rm = TRUE)) %>%
# ggplot(aes(x = year, y = mean)) +
# geom_point() +
# facet_wrap(~hovedtype)
# 2022 does not stand out as in the Sentinel data, so we keep it
ModisNDVI.natopen <- ModisNDVI.natopen %>%
group_by(id, year) %>%
filter(mean == max(mean, na.rm = TRUE))
# checking time series for Landsat
# LandsatNDVI.natopen %>%
# group_by(id, year) %>%
# filter(mean == max(mean, na.rm = TRUE)) %>%
# ggplot(aes(x = year, y = mean)) +
# geom_point() +
# facet_wrap(~hovedtype)
# nothing worrying to see here either
LandsatNDVI.natopen <- LandsatNDVI.natopen %>%
group_by(id, year) %>%
filter(mean == max(mean, na.rm = TRUE))
# transformation of NDVI scale to beta scale
# SentinelNDVI.natopen$mean_beta <- (SentinelNDVI.natopen$mean + 1) / 2
ModisNDVI.natopen$mean_beta <- (ModisNDVI.natopen$mean + 1) / 2
LandsatNDVI.natopen$mean_beta <- (LandsatNDVI.natopen$mean + 1) / 2
# check if there's any 0s or 1s (which beta cannot handle)
# summary(SentinelNDVI.natopen$mean_beta) # ok
# summary(ModisNDVI.natopen$mean_beta) # ok
# summary(LandsatNDVI.natopen$mean_beta)
# replace 1s in Landsat data with 0.9999
LandsatNDVI.natopen <- LandsatNDVI.natopen %>%
mutate(mean_beta = replace(mean_beta, mean_beta == 1, 0.9999))
# check if the three Satellite objects have the same structure (for concatenating them)
# names(SentinelNDVI.natopen)
# names(ModisNDVI.natopen)
# names(LandsatNDVI.natopen)
# Sentinel and Landsat have each an extra column -> omit them when concatenating further below
# one column is named slightly differently in the Sentinel data -> rename it
SentinelNDVI.natopen <- SentinelNDVI.natopen %>%
dplyr::rename("system.index" = "system:index")
# check if they have the same geometry
# st_crs(SentinelNDVI.natopen)
# st_crs(ModisNDVI.natopen)
# st_crs(LandsatNDVI.natopen)
# all good
# add an increment to the year variable to avoid overlapping data being hidden in figures
SentinelNDVI.natopen$year_jit <- SentinelNDVI.natopen$year + 0.3
ModisNDVI.natopen$year_jit <- ModisNDVI.natopen$year - 0.3
LandsatNDVI.natopen$year_jit <- LandsatNDVI.natopen$year
# concatenate the three Satellite objects
allSatNDVI.natopen <- rbind(
SentinelNDVI.natopen[, !names(SentinelNDVI.natopen) %in% "subtype"],
ModisNDVI.natopen,
LandsatNDVI.natopen[, !names(LandsatNDVI.natopen) %in% "column_label"]
)
# add variable for Satellite identity
allSatNDVI.natopen$Sat <- c(
rep("Sentinel", nrow(SentinelNDVI.natopen)),
rep("Modis", nrow(ModisNDVI.natopen)),
rep("Landsat", nrow(LandsatNDVI.natopen))
)
allSatNDVI.natopen$Sat <- factor(allSatNDVI.natopen$Sat, levels = c("Sentinel", "Modis", "Landsat"))
# levels(allSatNDVI.natopen$Sat)Now we can plot the time series for each main ecosystem type, showing each satellite time series separately:
# plot
allSatNDVI.natopen %>%
ggplot(aes(x = year_jit, y = mean, color = Sat)) +
geom_point() +
ggtitle("NDVI across time") +
labs(y = "NDVI values", x = "Year") +
facet_wrap(~hovedtype, ncol = 1)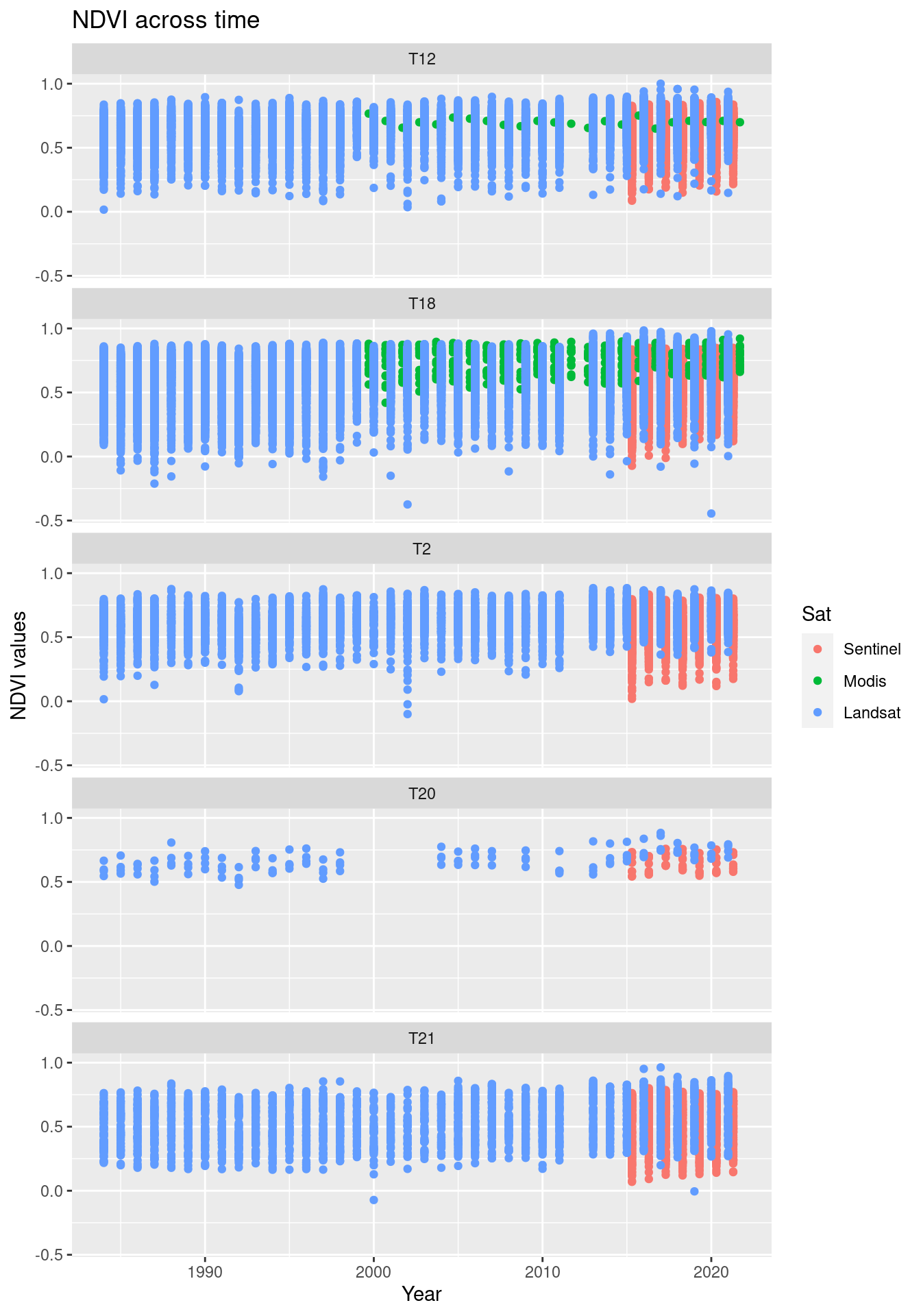
Figure 13.14: Comparing the NDVI time series in the three data sets.
It is quite obvious that the NDVI values from the three satellites are not quantitatively comparable. They vary both in their placement along the y-axis and in their variance. Modis data are are basically only available for flood plains (T18), as the other ecosystems types’ polygons are too small for the Modis pixel size.
We can test if there are consistent temporal changes in NDVI by running regressions including year as a covariate.
We first investigate a model testing NDVI as a function of year and main ecosystem type for polygons in good condition, and we do so separately for Sentinel and Landsat.
model.natopen.time.GodTilst.Sent <- glmmTMB(mean_beta ~ year * hovedtype + (1 | id), family = beta_family(), data = SentinelNDVI.natopen[SentinelNDVI.natopen$tilstand == "God", ])
model.natopen.time.GodTilst.Land <- glmmTMB(mean_beta ~ year * hovedtype + (1 | id), family = beta_family(), data = LandsatNDVI.natopen[LandsatNDVI.natopen$tilstand == "God", ])
summary(model.natopen.time.GodTilst.Sent)$coefficients$cond
#> Estimate Std. Error z value
#> (Intercept) -36.935300701 2.671601660 -13.825153
#> year 0.019061057 0.001323928 14.397357
#> hovedtypeT18 -18.746226142 3.158582045 -5.935013
#> hovedtypeT2 29.313518977 4.677147986 6.267392
#> hovedtypeT20 34.348239797 22.307347905 1.539772
#> hovedtypeT21 30.640990969 9.317135637 3.288671
#> year:hovedtypeT18 0.009273977 0.001565284 5.924788
#> year:hovedtypeT2 -0.014621002 0.002317759 -6.308249
#> year:hovedtypeT20 -0.017037041 0.011054315 -1.541212
#> year:hovedtypeT21 -0.015302734 0.004617052 -3.314395
#> Pr(>|z|)
#> (Intercept) 1.797309e-43
#> year 5.376061e-47
#> hovedtypeT18 2.938219e-09
#> hovedtypeT2 3.671455e-10
#> hovedtypeT20 1.236158e-01
#> hovedtypeT21 1.006617e-03
#> year:hovedtypeT18 3.127005e-09
#> year:hovedtypeT2 2.822102e-10
#> year:hovedtypeT20 1.232652e-01
#> year:hovedtypeT21 9.184164e-04
summary(model.natopen.time.GodTilst.Land)$coefficients$cond
#> Estimate Std. Error z value
#> (Intercept) -22.352086552 0.4510618533 -49.5543713
#> year 0.011956021 0.0002251119 53.1114514
#> hovedtypeT18 -4.475031773 0.5379636781 -8.3184645
#> hovedtypeT2 4.869272134 0.9851027104 4.9429081
#> hovedtypeT20 -2.778415547 4.2246325934 -0.6576703
#> hovedtypeT21 4.502139369 1.8867783558 2.3861517
#> year:hovedtypeT18 0.002214750 0.0002684923 8.2488402
#> year:hovedtypeT2 -0.002509721 0.0004915495 -5.1057333
#> year:hovedtypeT20 0.001404388 0.0021091469 0.6658559
#> year:hovedtypeT21 -0.002413297 0.0009412395 -2.5639570
#> Pr(>|z|)
#> (Intercept) 0.000000e+00
#> year 0.000000e+00
#> hovedtypeT18 8.911016e-17
#> hovedtypeT2 7.696578e-07
#> hovedtypeT20 5.107500e-01
#> hovedtypeT21 1.702573e-02
#> year:hovedtypeT18 1.599391e-16
#> year:hovedtypeT2 3.295142e-07
#> year:hovedtypeT20 5.055032e-01
#> year:hovedtypeT21 1.034864e-02There’s an increase in NDVI over time in both satellite time series in T12 (coastal meadows) and T18 (flood plains) in good condition. In the Sentinel data this pattern is absent for T2 and T21, in the Landsat data the increase is reduced.
We can check if these temporal changes in T12 and T18, as well as for T21 in Southern Norway, vary between condition classes?
model.natopen.time.tilst.T12.Sent <- glmmTMB(mean_beta ~ year * tilstand + (1 | id), family = beta_family(), data = SentinelNDVI.natopen[SentinelNDVI.natopen$hovedtype %in% c("T12"), ])
model.natopen.time.tilst.T12.Land <- glmmTMB(mean_beta ~ year * tilstand + (1 | id), family = beta_family(), data = LandsatNDVI.natopen[LandsatNDVI.natopen$hovedtype %in% c("T12"), ])
model.natopen.time.tilst.T18.Sent <- glmmTMB(mean_beta ~ year * tilstand + (1 | id), family = beta_family(), data = SentinelNDVI.natopen[SentinelNDVI.natopen$hovedtype %in% c("T18"), ])
model.natopen.time.tilst.T18.Land <- glmmTMB(mean_beta ~ year * tilstand + (1 | id), family = beta_family(), data = LandsatNDVI.natopen[LandsatNDVI.natopen$hovedtype %in% c("T18"), ])
model.natopen.time.tilst.T21.Sent <- glmmTMB(mean_beta ~ year * tilstand + (1 | id), family = beta_family(), data = SentinelNDVI.natopen[SentinelNDVI.natopen$hovedtype %in% c("T21") & SentinelNDVI.natopen$region == "Southern Norway", ])
model.natopen.time.tilst.T21.Land <- glmmTMB(mean_beta ~ year * tilstand + (1 | id), family = beta_family(), data = LandsatNDVI.natopen[LandsatNDVI.natopen$hovedtype %in% c("T21") & LandsatNDVI.natopen$region == "Southern Norway", ])
summary(model.natopen.time.tilst.T12.Sent)$coefficients$cond
#> Estimate Std. Error
#> (Intercept) -3.710345e+01 2.075499655
#> year 1.914584e-02 0.001028500
#> tilstandModerat 1.530732e+01 5.138673876
#> tilstandRedusert 2.150146e+01 10.203836208
#> tilstandSvaert_redusert -2.396413e-01 26.998352055
#> year:tilstandModerat -7.623323e-03 0.002546438
#> year:tilstandRedusert -1.070133e-02 0.005056427
#> year:tilstandSvaert_redusert 2.038877e-04 0.013379253
#> z value Pr(>|z|)
#> (Intercept) -17.876874751 1.785702e-71
#> year 18.615295922 2.415221e-77
#> tilstandModerat 2.978845594 2.893365e-03
#> tilstandRedusert 2.107193279 3.510083e-02
#> tilstandSvaert_redusert -0.008876147 9.929180e-01
#> year:tilstandModerat -2.993719944 2.755988e-03
#> year:tilstandRedusert -2.116382234 3.431231e-02
#> year:tilstandSvaert_redusert 0.015239097 9.878414e-01
summary(model.natopen.time.tilst.T18.Sent)$coefficients$cond
#> Estimate Std. Error
#> (Intercept) -5.553334e+01 2.837477867
#> year 2.826069e-02 0.001406121
#> tilstandModerat 3.982841e+00 6.138784981
#> tilstandRedusert -1.077785e+00 9.734943643
#> tilstandSvaert_redusert 1.872128e+01 16.596270829
#> year:tilstandModerat -1.924304e-03 0.003042232
#> year:tilstandRedusert 4.953817e-04 0.004824305
#> year:tilstandSvaert_redusert -9.379814e-03 0.008224452
#> z value Pr(>|z|)
#> (Intercept) -19.5713738 2.712696e-85
#> year 20.0983280 7.632194e-90
#> tilstandModerat 0.6487995 5.164680e-01
#> tilstandRedusert -0.1107130 9.118439e-01
#> tilstandSvaert_redusert 1.1280413 2.593025e-01
#> year:tilstandModerat -0.6325304 5.270403e-01
#> year:tilstandRedusert 0.1026846 9.182133e-01
#> year:tilstandSvaert_redusert -1.1404789 2.540868e-01
summary(model.natopen.time.tilst.T21.Sent)$coefficients$cond
#> Estimate Std. Error z value
#> (Intercept) 35.805280925 17.145006418 2.0883796
#> year -0.017094995 0.008495813 -2.0121670
#> tilstandModerat -10.342574293 20.537961983 -0.5035833
#> tilstandRedusert -46.415364291 33.385627772 -1.3902798
#> year:tilstandModerat 0.004988819 0.010177130 0.4901990
#> year:tilstandRedusert 0.022687670 0.016543610 1.3713857
#> Pr(>|z|)
#> (Intercept) 0.03676361
#> year 0.04420234
#> tilstandModerat 0.61455424
#> tilstandRedusert 0.16444393
#> year:tilstandModerat 0.62399308
#> year:tilstandRedusert 0.17025476
summary(model.natopen.time.tilst.T12.Land)$coefficients$cond
#> Estimate Std. Error
#> (Intercept) -2.257603e+01 0.3592224744
#> year 1.207285e-02 0.0001792247
#> tilstandModerat 9.942636e-01 1.0480499362
#> tilstandRedusert 2.407909e+00 2.3128394175
#> tilstandSvaert_redusert 1.220670e+01 4.3590250180
#> year:tilstandModerat -5.106564e-04 0.0005228819
#> year:tilstandRedusert -1.218127e-03 0.0011538302
#> year:tilstandSvaert_redusert -5.887491e-03 0.0021752446
#> z value Pr(>|z|)
#> (Intercept) -62.8469354 0.000000000
#> year 67.3615626 0.000000000
#> tilstandModerat 0.9486796 0.342783587
#> tilstandRedusert 1.0411052 0.297826750
#> tilstandSvaert_redusert 2.8003288 0.005105059
#> year:tilstandModerat -0.9766190 0.328757795
#> year:tilstandRedusert -1.0557249 0.291093905
#> year:tilstandSvaert_redusert -2.7065881 0.006797854
summary(model.natopen.time.tilst.T18.Land)$coefficients$cond
#> Estimate Std. Error
#> (Intercept) -26.684682919 0.3198164900
#> year 0.014097082 0.0001596524
#> tilstandModerat -8.865995020 0.8288648197
#> tilstandRedusert -7.328083962 1.3230496265
#> tilstandSvaert_redusert -5.653610976 2.0758288689
#> year:tilstandModerat 0.004455210 0.0004138240
#> year:tilstandRedusert 0.003638674 0.0006605013
#> year:tilstandSvaert_redusert 0.002732487 0.0010359880
#> z value Pr(>|z|)
#> (Intercept) -83.437483 0.000000e+00
#> year 88.298593 0.000000e+00
#> tilstandModerat -10.696551 1.056370e-26
#> tilstandRedusert -5.538782 3.045818e-08
#> tilstandSvaert_redusert -2.723544 6.458564e-03
#> year:tilstandModerat 10.765952 4.984396e-27
#> year:tilstandRedusert 5.508958 3.609632e-08
#> year:tilstandSvaert_redusert 2.637566 8.350328e-03
summary(model.natopen.time.tilst.T21.Land)$coefficients$cond
#> Estimate Std. Error z value
#> (Intercept) -17.963080316 3.781165685 -4.7506726
#> year 0.009523126 0.001884278 5.0539924
#> tilstandModerat 10.897562178 3.988209496 2.7324448
#> tilstandRedusert 2.473501410 4.792342126 0.5161362
#> year:tilstandModerat -0.005429927 0.001987436 -2.7321276
#> year:tilstandRedusert -0.001340730 0.002387883 -0.5614723
#> Pr(>|z|)
#> (Intercept) 2.027411e-06
#> year 4.326688e-07
#> tilstandModerat 6.286621e-03
#> tilstandRedusert 6.057593e-01
#> year:tilstandModerat 6.292677e-03
#> year:tilstandRedusert 5.744756e-01The temporal NDVI increase has been stronger in flood plains that are in reduced ecological condition, but only in the Landsat time series. The other ecosystem types do not show any obvious patterns.
13.8 Overall conclusion
NDVI in natopen ecosystem varies very little with condition. The variance and thus overlap between condition classes and ecosystem types is large. Exceptions are sand dunes in Southern Norway, which show reduced NDVI under deteriorating condition in the Sentinel data, and flood plains nationally, where areas in deteriorating condition show a stronger increase in NDVI over time. Other than for these two phenomena, NDVI does not appear as a sensitive measure of ecological condition in natopen systems.
Beyond these considerations, there are two general issues which limit a more comprehensive and robust application of satellite based NDVI-data in an ecological condition context:
-
We are lacking ecosystem maps for natopen ecosystems
The analysis at hand clearly shows that different natopen ecosystem types display different greenness levels and thus need to be evaluated separately. Thus, we need ecosystem maps, that allow us to treat NDVI values for at least the different major ecosystem types within natopens separately.
-
We are lacking ecosystem maps for natopen ecosystems
The analysis at hand clearly shows that different natopen ecosystem types display different greenness levels and thus need to be evaluated separately. Thus, we need ecosystem maps, that allow us to treat NDVI values for at least the different major ecosystem types within natopens separately.