5 Alien species
Norwegian name: Fravær av fremmede arter
Author and date:
Anders L. Kolstad
September 2023
Ecosystem |
Økologisk egenskap |
ECT class |
|---|---|---|
Våtmark, Naturlig åpne områder under skoggrensa, Semi-naturlig mark |
Biologisk mangfold |
B1 Compositional state characteristics |
5.1 Introduction
This indicator represent the the ecological on-site effect from alien species. In practice, the indicator is restricted to alien vascular plants. Whilst the introduction of alien species is best considered a pressure variable, the relative abundance of alien species on a given location is seen here as a manifestation of this negative anthropogenic impact, and is therefore a valid condition indicator.
A related variable has been used previously for alpine and forest ecosystems in Norway. These indicators were based on ANO, a national monitoring program, where alien species cover was estimated to the closest whole percent. The upper and lower reference levels that was used back then was 0 or 100% of the species composition made up of alien species, respectively. The threshold value between good and reduced condition was defined as 5%. In this approach, the indicator represented the relative area with an absence of alien species. It is in a way the flip-side of alien species abundance. The latter was said to be a pressure variable, whilst the former reacts as direct and linear consequence of changes to this variable, and was therefore accepted as a condition indicator. We do not make this distinction here.
This time we are using the nature type mapping dataset which records the assumed effect of alien species, rather than a direct measure of abundance such as percentage cover. The recording scale is called R7 (Fig. 5.1) and is an ordinal scale which has a non-linear relationship with percentage cover recorded in ANO (Fig. 5.2). In order to combine these two data sets, we must convert one of these scales to match the other.
Here I base the indicator on the R7 scale, since this is, presumably, the bigger data set. I therefore convert percentage cover into R7 classes based on what I can interpret from Fig. 5.2.
Upper reference value is then 1, and lower reference value is 7, on the R7 scale. For the threshold value I will set this to value 3 on the R7 scale. This is based on interpretation by the author and based of the definition of this value in Fig. 5.1. Step 3 on the R7 scale is the step that, concordantly, best matches the 5% threshold in the old approach, as seen from Fig. 5.2.
The indicator is calculated separately for the three ecosystems, but all nature types associated with the same ecosystem are pooled and treated equally. This means we assume the nature types that are mapped and which we have data from are, when pooled, representative for the main ecosystem. This is less true for Naturally open ecosystems than it is for the other two. You can read more about that here.
knitr::include_graphics("images/R7 scale.PNG")
Figure 5.1: The R7 scale used when recording the effect of alien species in the nature type monitoring program
knitr::include_graphics("images/fremmedart_prosentVSinnslag.PNG")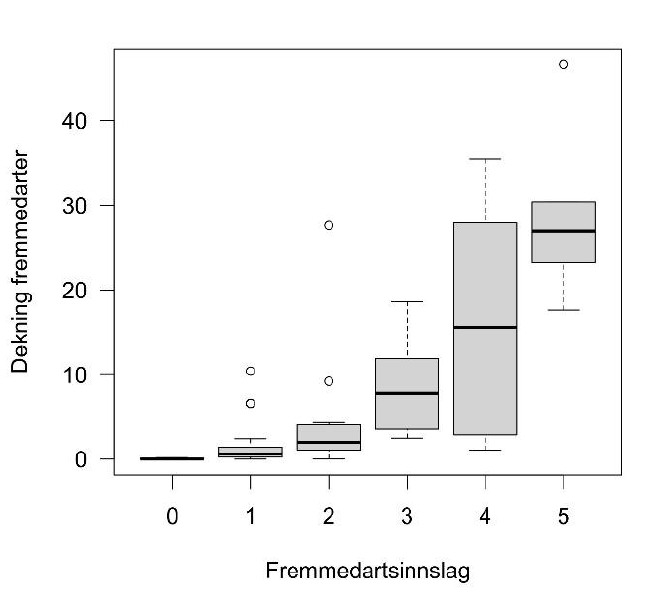
Figure 5.2: Comparing the R7 scale (x axis) which is used in the nature type monitoring program with percentage cover (y-axis), which is how alien species is recorded in GRUK. I am assuming the x axis is shifted downwards compared to the original R7 scale which range from 1 to 7, so that a value of 0 here equals an R7 value of 1. Note also that this relationship is based on limited data from just one nature type and in smaller diameter circles than the other data we use in this indicator. Cropped from Evju et al (2022).
Since the nature type data is not sampled in a systematic or random way, we must take extra care not to over-extrapolate in space. We delineate homogeneous impact areas (HIA) based on four classes of increasing infrastructure intersected with municipality borders, and we say that if we have more than n data points then this field data is representative inside the entire HIA. In a related indicator we used the accounting areas to define the HIA (5 accounting areas in Norway), in addition to the infrastructure classes. For this indicator, we expect more gradients also inside accounting areas, and therefore we define HIAs based on municipalities. This means that there will be more missing data in our final indicator maps, since not all municipalities will have sufficient data points to estimate indicator values.
We then calculate an area weighted mean (and error) indicator value for each HIA, as long as there is more than n data points for a given combination of HIA and municipality.
Here a general workflow for the calculation of the indicator.
Import Nature type data data set (incl. GRUK) and ANO data set
Convert ANO points to polygons
Combine data sets
Scale the
alien speciesvariable based on reference values.Define homogeneous impact areas (HIA) based on an infrastructure index and municipalities
Aggregate and spread indicator value across HIAs (and municipalities)
Confirm relationship between infrastructure index and indicator values to justify the extrapolation
TO DO: Prepare ecosystem delineation maps and use these to mask the extrapolated indicator maps
Spatial aggregation of indicator values and uncertainties to accounting areas
Export indicator maps and regional extrapolated maps
5.2 About the underlying data
The indicator uses a data set from a standardised field survey of nature types. You can read more about this data set from my preliminary analyses here. See also the official site of the Environment Agency. I also import a data set called ANO, which you can read about here.
5.2.1 Representativity in time and space
The nature type mapping is not random and cannot be said to be area representative. This will not improve over time either.
The ANO data set however, is area representative. The data is from 2018 to present. The data from one field season usually becomes available early the following year.
Regarding update frequency, the Nature type data set is not replicated, nor will it be in the future. We must therefore trust that the selection criteria for which areas to survey will not change drastically and systematically over time. For example, we are now surveying a lot in pressure areas, meaning lowland areas close to human population centers. If we in the future allocate more time to surveying wilderness areas, then the indicator becomes biased. On the other hand, ANO is replicated every 5 years.
5.2.2 Original units
The variables are recorded on a unitless seven-step ordinal scale (Fig. 5.1) or a as a percentage cover of alien species.
5.2.3 Temporal coverage
The data goes back to 2018. I therefore bulk all the data from 2018 to 2022 into one time step. I then use the mean date for the raw data, and define the variable as belonging to the year 2020 (read more here).
5.2.4 Aditional comments about the dataset
For a run through of the nature type data set, see here.
5.3 Ecosystem characteristic
5.3.1 Norwegian standard
The indicator is tagged to the Økologisk egenskap called Biologisk mangfold. This emphasises the negative effect that alien species have on for example supressing or excluding native species. In some cases, alien species can also affect nutrient cycling or recruitment and could then also be appropriate under funksjonelt viktige arter og strukturer.
5.4 Collinearities with other indicators
Alien species is not thought to exhibit collinearity with any other indicator at the present.
5.5 Reference condition and values
5.5.1 Reference condition
The reference condition is one with minimal negative human impact. This is also true for semi-natural ecosystems. In a sense, the reference condition is pre-1800, since the Alien Species List of Norway only contains species established after 1800.
5.5.2 Reference values, thresholds for defining good ecological condition, minimum and/or maximum values
Upper = 1 (R7 scale), corresponding to 0% alien species
Threshold = 3 (R7 scale), corresponding to about 2-5% alien species cover.
Lower = 7 (R7 scale), corresponding to 100% alien species cover.
For a discussion around the reference values, see here
Read about the normalisation here.
5.6 Uncertainties
Uncertainties/errors are estimated for aggregated indicator values by bootstrapping individual indicator values 1000 times and calculating a distribution of area weighted means. This uncertainty is different from the spatial variation which we could get more straightforward without bootstrapping. When aggregating a second time, from homogeneous impact areas to accounting areas, we assume a normal distribution around the indicator values, with the already mentioned errors, and sample n times from these and combine the resamples into an a new, area-weighted, distribution. The errors for the accounting areas thus represents both the spatial variation and the precision of the indicator values within the accounting areas.
5.7 References
Evju, M., Skrindo, A.B. & Solstad, H. (red.) 2022. Overvåking av åpen grunnlendt kalkmark 2021‒2024. Årsrapport 2022. NINA Rapport 2195. Norsk institutt for naturforskning.
5.8 Analyses {analyses-ali}
5.8.1 Data sets
5.8.1.1 Nature type mapping
This indicator uses the data set
Naturtyper etter Miljødirektoratets Instruks, which can be found
here.
See also here for a detailed description of the data set.
We also have a separate summary file where the nature types are manually mapped to the NiN variables and to the correct NiN-main types. We can use this to find the nature types of interest.
naturetypes_summary_import <- readRDS("data/naturetypes/natureType_summary.rds")We are only interested in mapping units that include our target variables. The variable fremmedartsinnslag (presence of alien species) is coded as 7FA.
myVars <- '7FA'
naturetypes_summary <- naturetypes_summary_import %>%
rowwise() %>%
mutate(keepers = sum(c_across(
all_of(myVars))>0, na.rm=T)) %>%
filter(keepers >0) %>%
select(Nature_type, NiN_mainType, Year)This deleted 30 nature types and left us with these 24 nature types where 7FA was recorded:
DT::datatable(naturetypes_summary)Importing and sub-setting the main data file, fix duplicate hovedøkosystem, calculate area, split one column in two, make numeric, and select target variables:
naturetypes <- sf::st_read(dsn = path) %>%
filter(naturtype %in% naturetypes_summary$Nature_type) %>%
mutate(hovedøkosystem = case_match(hovedøkosystem,
"naturligÅpneOmråderILavlandet" ~ "naturligÅpneOmråderUnderSkoggrensa",
.default = hovedøkosystem),
area = st_area(.)) %>%
separate_rows(ninBeskrivelsesvariable, sep=",") %>%
separate(col = ninBeskrivelsesvariable,
into = c("NiN_variable_code", "NiN_variable_value"),
sep = "_",
remove=F) %>%
mutate(NiN_variable_value = as.numeric(NiN_variable_value)) %>%
filter(NiN_variable_code %in% myVars)
#> Reading layer `Naturtyper_nin_0000_norge' from data source
#> `/data/R/GeoSpatialData/Habitats_biotopes/Norway_Miljodirektoratet_Naturtyper_nin/Original/Naturtyper_nin_0000_norge_25833_FILEGDB/Naturtyper_nin_0000_norge_25833_FILEGDB.gdb'
#> using driver `OpenFileGDB'
#> Simple feature collection with 117427 features and 36 fields
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: -74953.52 ymin: 6448986 xmax: 1075081 ymax: 7921284
#> Projected CRS: ETRS89 / UTM zone 33N
ggplot(data = naturetypes, aes(x = naturtype, fill = hovedøkosystem))+
geom_bar()+
coord_flip()+
theme_bw(base_size = 10)+
theme(legend.position = "top",
legend.title = element_blank(),
legend.direction = "vertical")+
guides(fill = "none")+
xlab("")+
ylab("Number of localities")+
facet_wrap(.~hovedøkosystem, ncol=1, scale="free")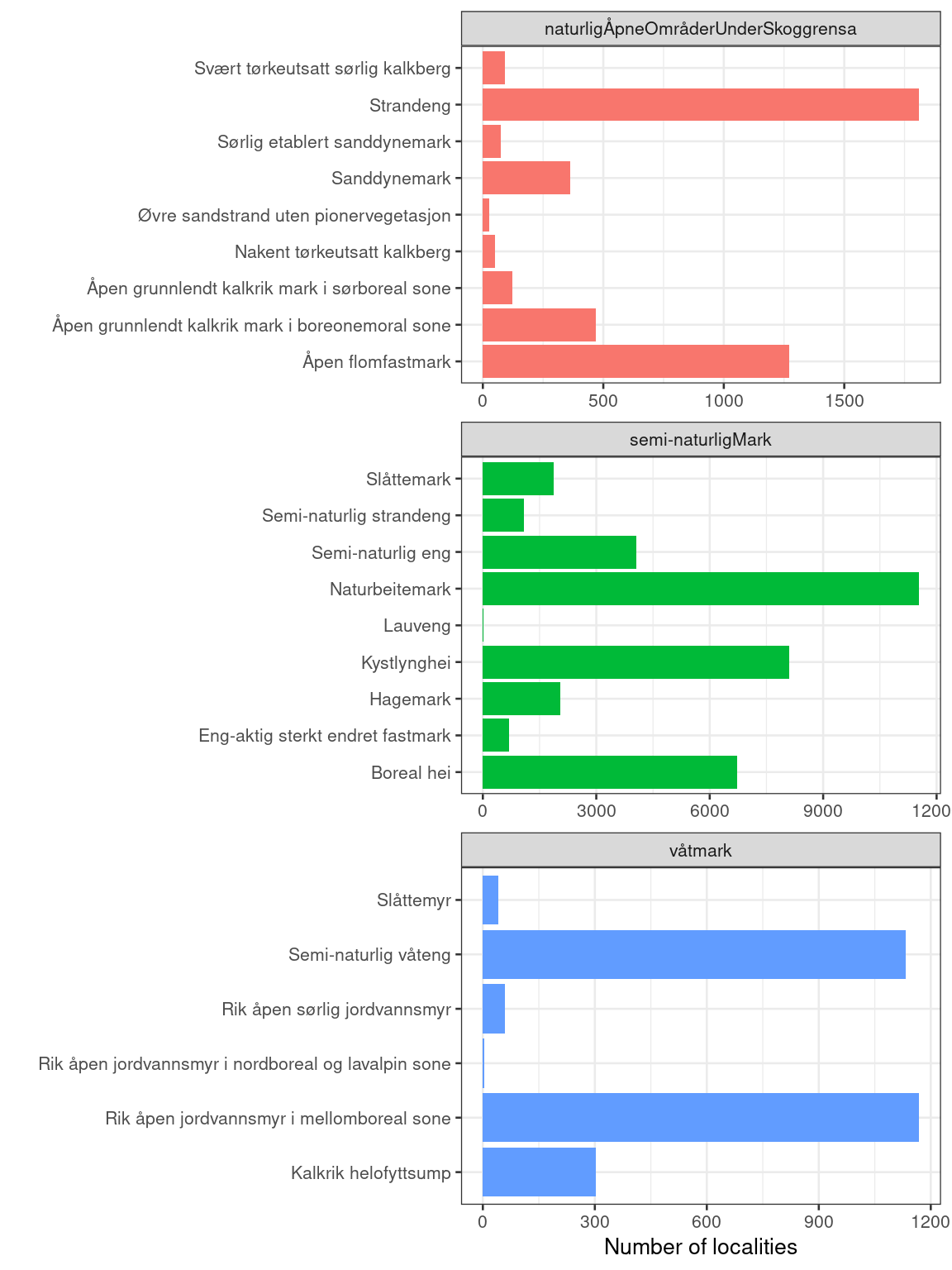
Figure 3.1: An overview of the naturetypes for which we will calculate the indicator.
Note that there is a lot more data for semi-natural ecosystem compared to the other two.
Column names starting with a number is problematic, so adding a prefix
naturetypes$NiN_variable_code <- paste0("var_", naturetypes$NiN_variable_code)Removing NA’s
naturetypes <- naturetypes[!is.na(naturetypes$NiN_variable_value),]Shift variable to start from 1 rather than from 0.
naturetypes$NiN_variable_value <- naturetypes$NiN_variable_value+1
ggplot(naturetypes, aes(x = NiN_variable_value))+
geom_histogram(fill="grey",
colour = "black",
binwidth = 1)+
theme_bw(base_size = 12)+
labs(x = "Alien species variable score") +
facet_wrap(.~hovedøkosystem, scales="free_y")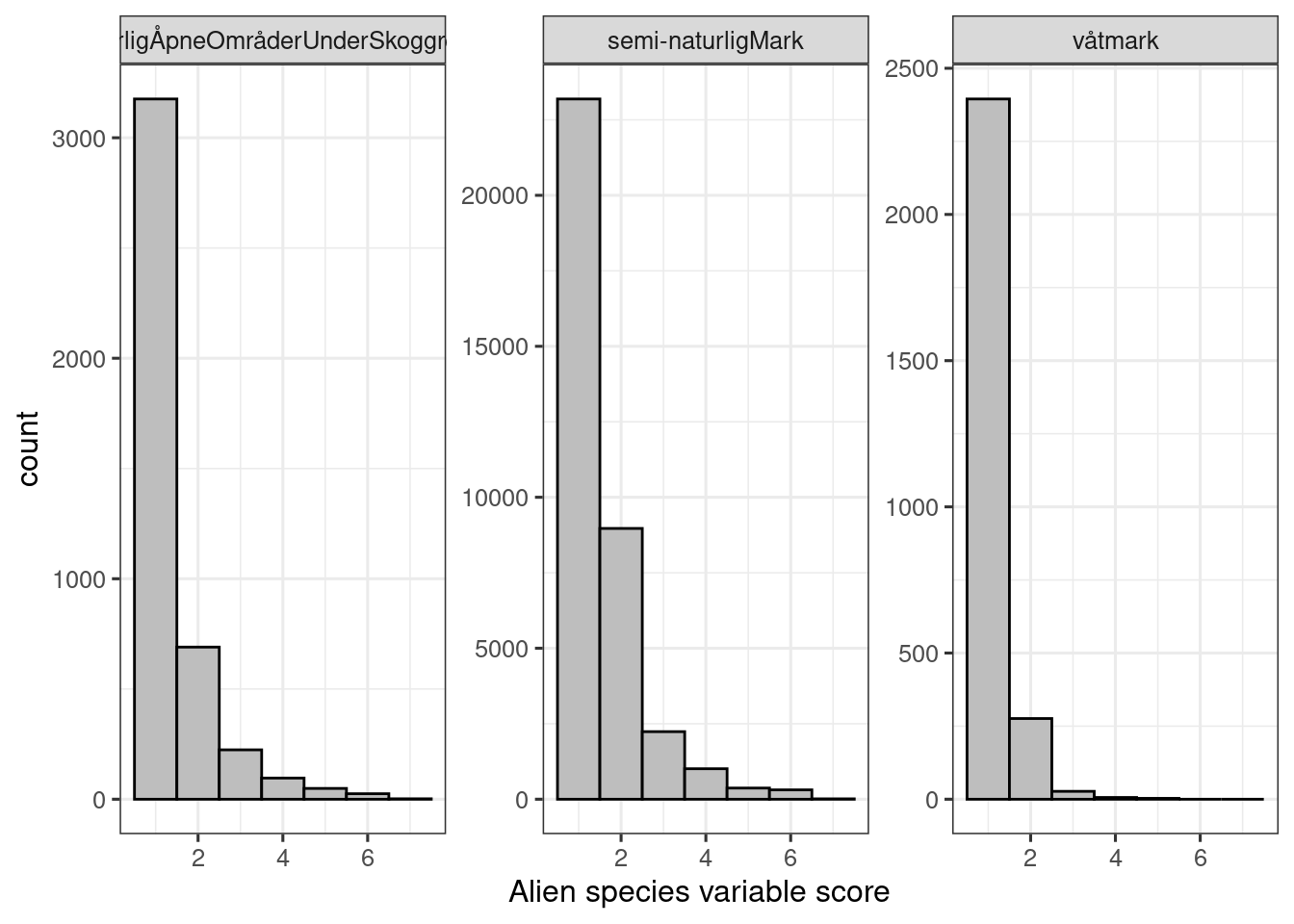
Figure 5.3: Alien species variable scores in the nature type data set.
It appears most localities are in good condition; actually, most localities have no alien species at all.
5.8.1.2 GRUK
This variable (7FA) is also recorded in
GRUK.
The nature type data set I’m working on here includes this data already
(presently only 2021 included). GRUK also records a related variable:
% cover in 5m radii circles, which is much more detailed. This data is
not published. In any case it is better to use the harmonized data set
in our case.
See also this GitHub issue.
5.8.1.3 ANO
Arealrepresentativ Naturovervåking (ANO) consist of 1000 systematically placed locations in Norway, each with 18 sample points. In each sample point, a circle of 250 m2 is inspected, and the main ecosystem is recorded.
The percentage cover of alien vascular plant is estimated, irrespective of main ecosystem type. In contrast to the nature type data set, ANO only looks at vascular plants, and then also only the three highest impact categories of the Alien Species List (SE, HI, PH). It is therefore not completely unproblematic to combine these to data sets, but we will do so anyway. We expect plants to be the by far most common species group to influence the 7FA variable as well. And similarly, we expect the three highest impact categories to contain the most widespread species, which will drive the 7FA variable more than the other categories.
ano_eco <- c("vaatmark", "naturlig_apne", "semi_naturlig_mark")
ano <- sf::st_read(paste0(pData, "Naturovervaking_eksport.gdb"),
layer = "ANO_SurveyPoint") %>%
dplyr::filter(hovedoekosystem_punkt %in% ano_eco) %>%
mutate(hovedoekosystem_punkt = case_match(hovedoekosystem_punkt,
"vaatmark" ~ "våtmark",
"naturlig_apne" ~ "naturligÅpneOmråderUnderSkoggrensa",
"semi_naturlig_mark" ~ "semi-naturligMark",
.default = hovedoekosystem_punkt))
#> Reading layer `ANO_SurveyPoint' from data source
#> `/data/P-Prosjekter2/41201785_okologisk_tilstand_2022_2023/data/Naturovervaking_eksport.gdb'
#> using driver `OpenFileGDB'
#> Simple feature collection with 8974 features and 71 fields
#> Geometry type: POINT
#> Dimension: XY
#> Bounding box: xmin: -51950 ymin: 6467050 xmax: 1094950 ymax: 7923950
#> Projected CRS: ETRS89 / UTM zone 33N
table(ano$aar)
#>
#> 2019 2021
#> 215 887This data set only contains data from year 2019 and 2021. We need to update this data set later. It is not clear why there is no data from 2020.
Each point/row here is 250 square meters. The data also contains information about how big a proportion of this area is made up of the dominant main ecosystem. However, there are 215 NA’s here, which is 20% of the data.
It appears the proportion of each circle that is made up of the dominant ecosystem was only recorded after year 2019. In fact, the main ecosystem was not recorded at all in 2019:
table(ano$hovedtype_250m2, ano$aar)
#>
#> 2019 2021
#> Åpen flomfastmark 0 1
#> Åpen grunnlendt mark 0 90
#> Åpen jordvannsmyr 0 417
#> Boreal hei 0 81
#> Fjellhei leside og tundra 0 5
#> Grøftet torvmark 0 5
#> Helofytt-ferskvannssump 0 3
#> Historisk skredmark 0 3
#> Isinnfrysingsmark 0 1
#> Kaldkilde 0 3
#> Kystlynghei 0 26
#> Løs sterkt endret fastmark 0 1
#> Myr- og sumpskogsmark 0 51
#> Nakent berg 0 35
#> Nedbørsmyr 0 53
#> Rasmark 0 23
#> Rasmarkhei og -eng 0 3
#> Semi-naturlig eng 0 44
#> Semi-naturlig myr 0 14
#> Semi-naturlig våteng 0 2
#> Skogsmark 0 3
#> Strandberg 0 5
#> Strandeng 0 2
#> Strandsumpskogsmark 0 2
#> Våtsnøleie og snøleiekilde 0 6I can remove the NA’s, and thus the 2019 data.
All of 2019 ANO data is excluded because of missing information
ano <- ano[!is.na(ano$andel_hovedoekosystem_punkt),]Let’s look at the variation in the recorded proportion of ecosystem cover
par(mar=c(5,6,4,2))
plot(ano$andel_hovedoekosystem_punkt[order(ano$andel_hovedoekosystem_punkt)],
ylab="Percentage of the 250 m2 area\ncovered by the main ecosystem")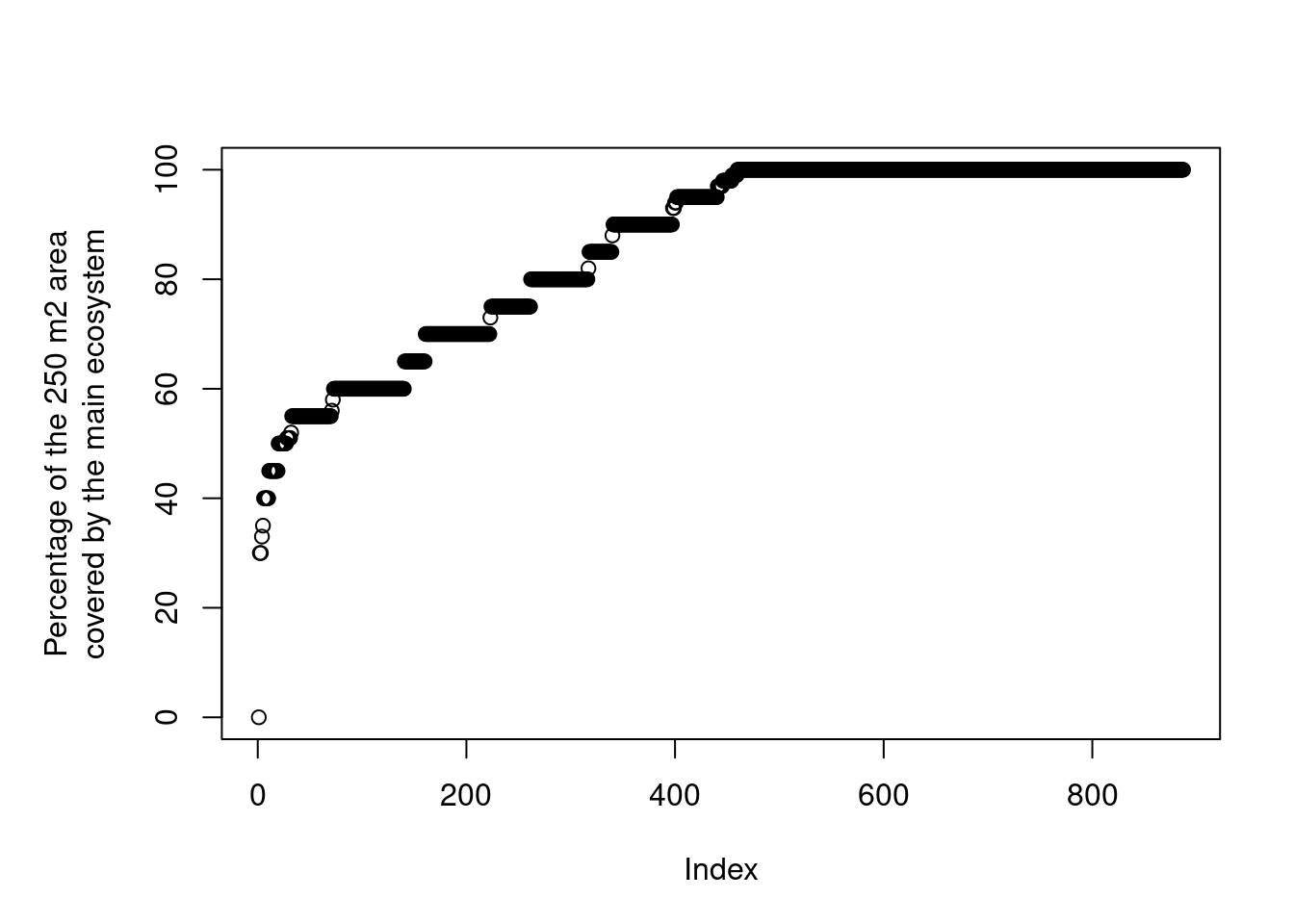
Figure 3.7: Distribution of the ANO variable andel_hovedoekosystem_punkt.
The zero in there is an obvious mistake. Removing it:
ano <- ano[ano$andel_hovedoekosystem_punkt>20,]Here’s another plot of the distribution of the same variable:
ggplot(ano, aes(x = andel_hovedoekosystem_punkt))+
geom_histogram(fill = "grey",
colour="black",
binwidth = 1)+
theme_bw(base_size = 12)+
xlab("Percentage cover of the main ecosystem\n in the 250m2 circle")+
scale_x_continuous(limits = c(0,101),
breaks = seq(0,100,10))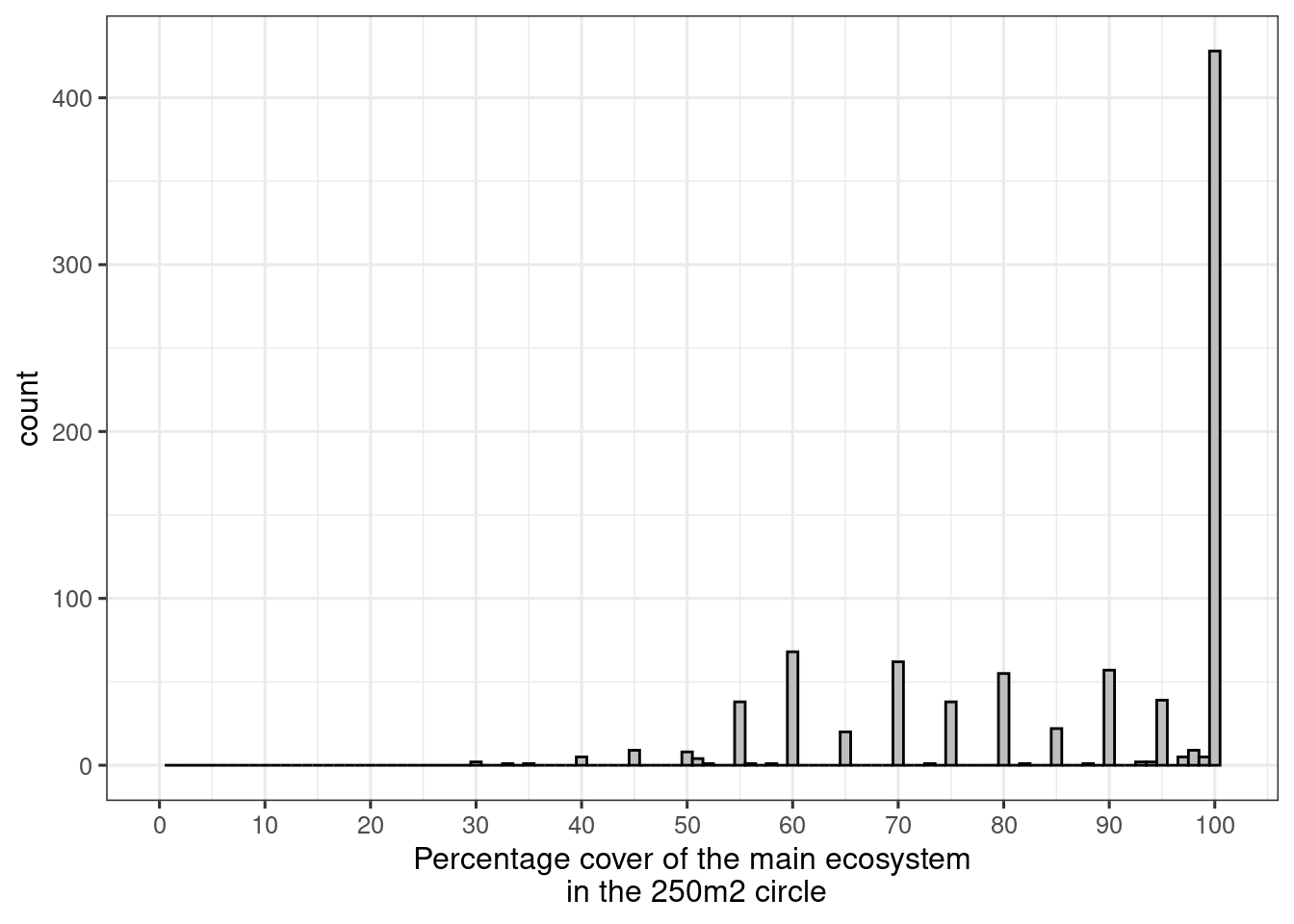
Figure 5.4: Percentage cover of the main ecosystem in the 250m2 circle
We can see that people tend to record the variable in steps of 5%, and that most sample points are 100% belonging to the same main ecosystem.
We want to use area weighting in this indicator, so we can use this percentage cover data to calculate the area. Note that both data sets use m2 as area units.
ano$area <- (ano$andel_hovedoekosystem_punkt/100)*250Let’s now look at the distribution of the variable. It is coded as fa_total_dekning.
First, there are 73 NA’s in this column which we can remove.
ano <- ano[!is.na(ano$fa_total_dekning),]Let us plot the distribution of values.
ggplot(ano, aes(x = fa_total_dekning))+
geom_histogram(fill="grey",
colour = "black",
binwidth = 1)+
theme_bw(base_size = 12)+
labs(x = "Percentage cover alien vascular plants") +
facet_wrap(.~hovedoekosystem_punkt, scales="free_y")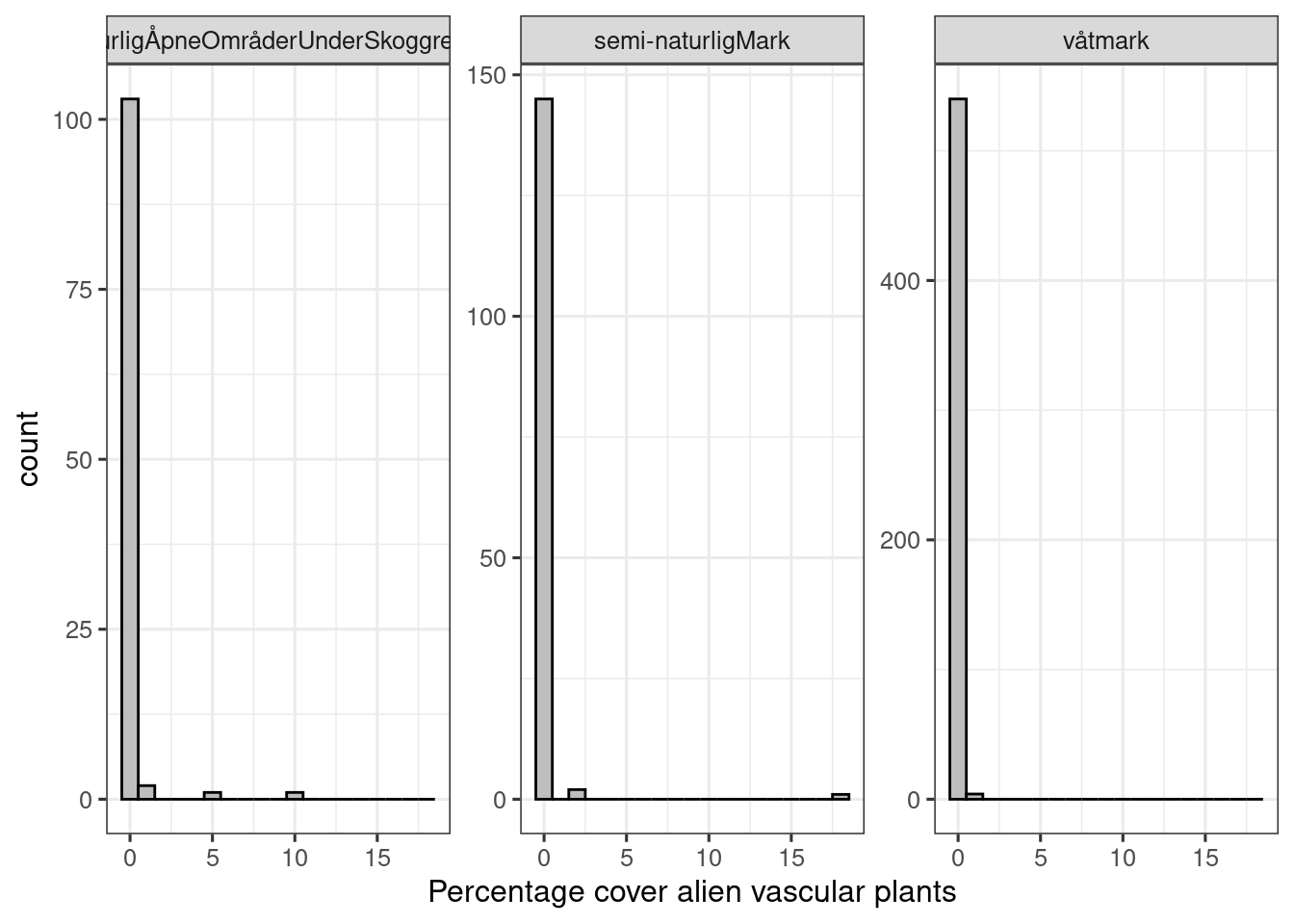
Figure 5.5: Distribution of percentage cover of alien plants variable in the ANO data set
The ANO localities seemingly have less alien plants in them than the nature type localities. This can be due to sampling biases in the latter.
Now I will convert these percentage cover values into 7FA classes. This is a critical step, since there is no one-to-one mapping here, but rather there is considerable overlap, as can be seen in Fig. 5.2.
ano <- ano %>%
mutate(var_7FA = case_when(
fa_total_dekning>90 ~ 7,
fa_total_dekning>25 ~ 6,
fa_total_dekning>10 ~ 5,
fa_total_dekning>5 ~ 4,
fa_total_dekning>2 ~ 3,
fa_total_dekning>1 ~ 2,
fa_total_dekning<1 ~ 1))
ggplot(ano, aes(x = var_7FA))+
geom_histogram(fill="grey",
colour = "black",
binwidth = 1)+
theme_bw(base_size = 12)+
labs(x = "Percentage cover alien vascular plants\n converted to the R7 scale") +
facet_wrap(.~hovedoekosystem_punkt, scales="free_y")
#> Warning: Removed 6 rows containing non-finite values
#> (`stat_bin()`).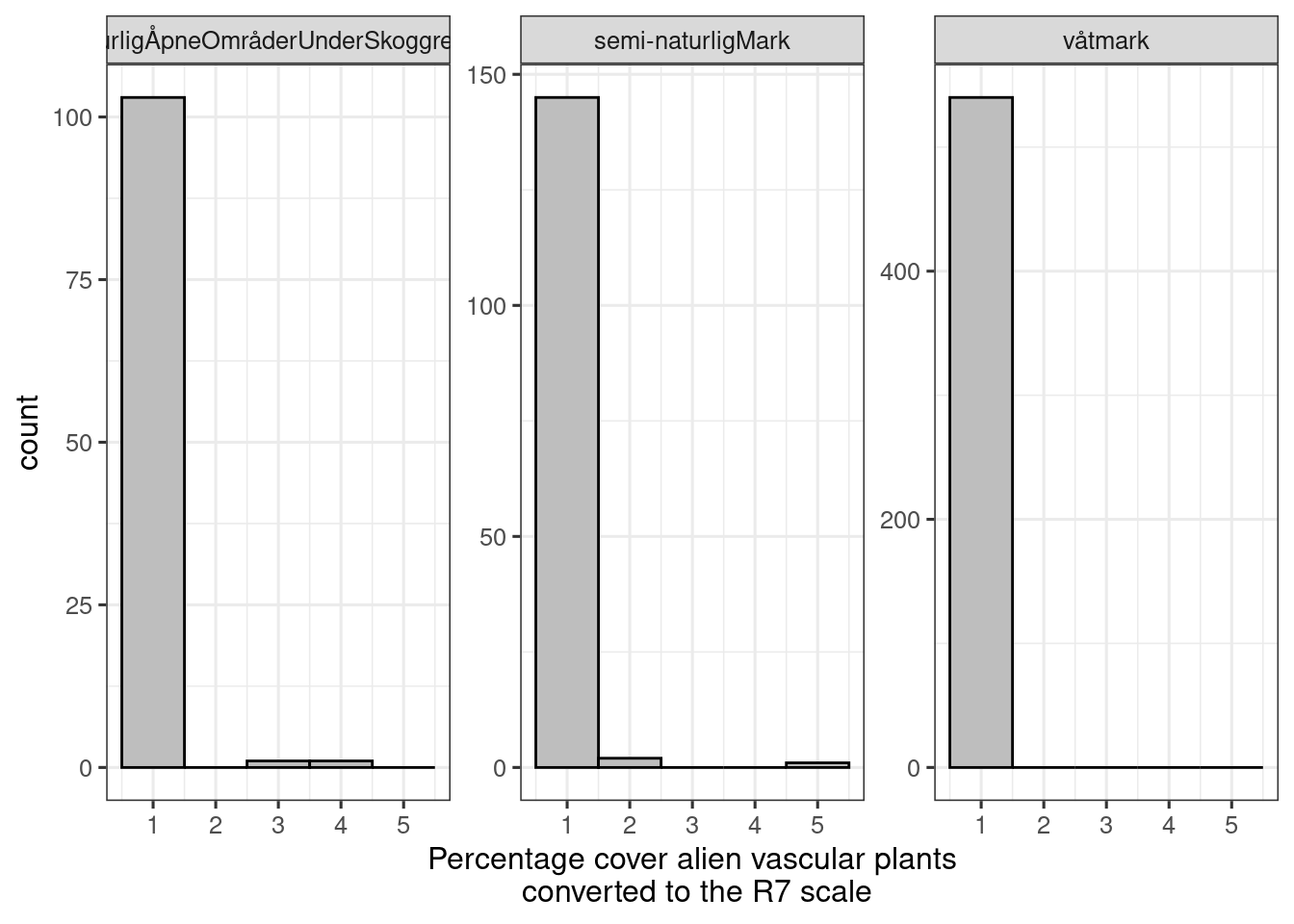
Figure 5.6: Distribution of R7 values in the ANO data set
5.8.1.3.1 Combine Naturtype data and ANO
We need to combine the nature type data set with the ANO data set. I
will add a column origin to show where the data comes from. I will
also add a column with the main ecosystem.
ano$origin <- "ANO"
naturetypes$origin <- "Nature type mapping"
ano$hovedøkosystem <- ano$hovedoekosystem_punkt
ano$kartleggingsår <- ano$aarFix class
naturetypes$kartleggingsår <- as.numeric(naturetypes$kartleggingsår)
naturetypes$area <- units::drop_units(naturetypes$area)I use dplyr::select to reduce the number of columns to keep things a
bit more tidy.
alien_data <- dplyr::bind_rows(select(ano,
GlobalID,
origin,
kartleggingsår,
hovedøkosystem,
area,
var_7FA,
SHAPE),
select(naturetypes,
identifikasjon_lokalId,
origin,
hovedøkosystem,
kartleggingsår,
area,
var_7FA = NiN_variable_value,
SHAPE))5.8.1.3.1.1 Points to polygons
The ANO data is point data and the nature type data is multipolygon:
unique(st_geometry_type(alien_data))
#> [1] POINT MULTIPOLYGON
#> 18 Levels: GEOMETRY POINT LINESTRING POLYGON ... TRIANGLEBecause later we will rasterize these data, we will convert the points to polygons. I use the area column to calculate a radius that gives that area.
alien_data_points <- alien_data %>%
mutate(g_type = st_geometry_type(.)) %>%
filter(g_type =="POINT") %>%
st_buffer(sqrt(alien_data$area/pi))Checking now that the new polygons have the area corresponding to the proportion of the point that was part of the same main ecosystem:
alien_data_points$area2 <- st_area(alien_data_points)
plot(alien_data_points$area, alien_data_points$area2,
xlab = "Target area",
ylab = "Area of the new polygons")
abline(0,1)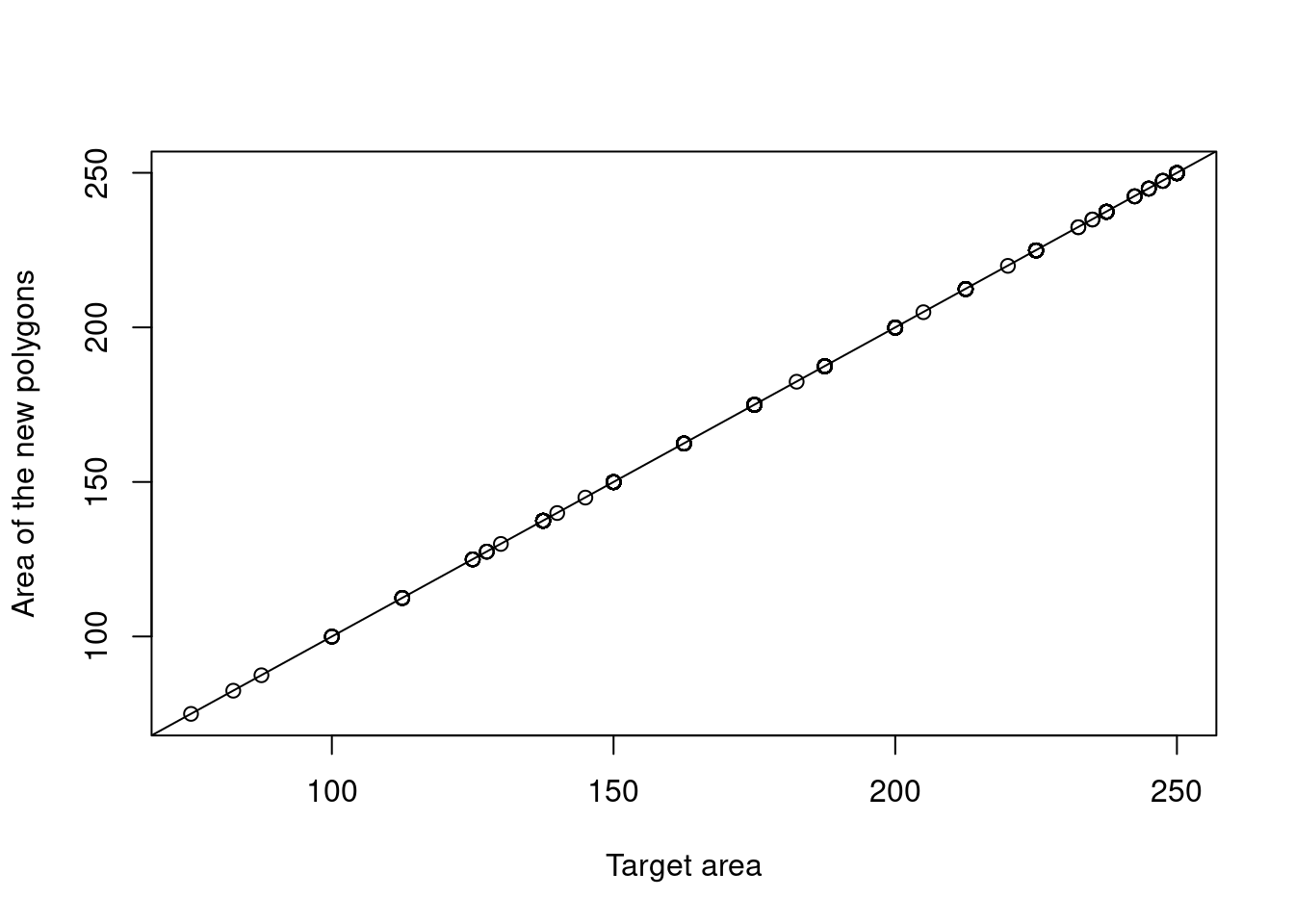
Figure 5.7: Checking that the area of the new polygons fall in line with the proportion of each point which is part of the main ecosystem.
The area calculation seems to have worked fine. Checking that the new data set contains only polygons.
alien_data_polygons <- alien_data %>%
mutate(g_type = st_geometry_type(.)) %>%
filter(g_type !="POINT")
alien_data <- bind_rows(alien_data_points, alien_data_polygons)
unique(st_geometry_type(alien_data))
#> [1] POLYGON MULTIPOLYGON
#> 18 Levels: GEOMETRY POINT LINESTRING POLYGON ... TRIANGLEOk.
5.8.1.4 Distribution of 7FA scores
temp <- as.data.frame(table(alien_data$var_7FA))
ggplot(temp, aes(x = Var1,
y = Freq))+
geom_bar(stat="identity",
fill="grey",
colour = "black")+
theme_bw(base_size = 12)+
labs(x = "7FA score",
y = "Number of localities")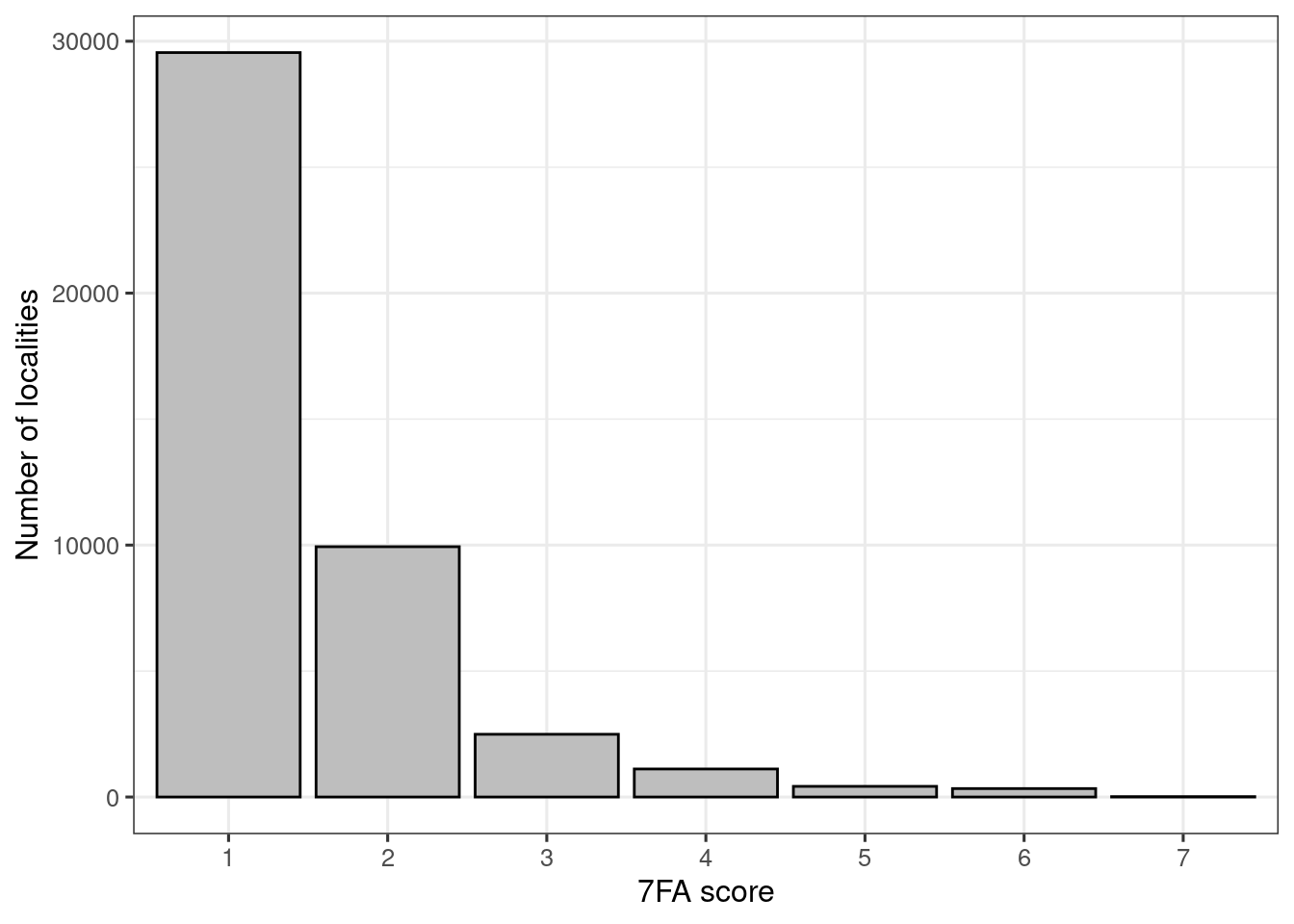
Figure 3.11: 7FA (alien species) scores (ANO Naturetype (and GRUK) data combined).
Let’s see the proportion of data points (not area) originating from each data set
temp <- as.data.frame(table(alien_data$origin))
ggplot(temp, aes(x = Var1,
y = Freq))+
geom_bar(stat="identity",
fill="grey",
colour = "black")+
theme_bw(base_size = 12)+
labs(x = "Data origin",
y = "Number of localities")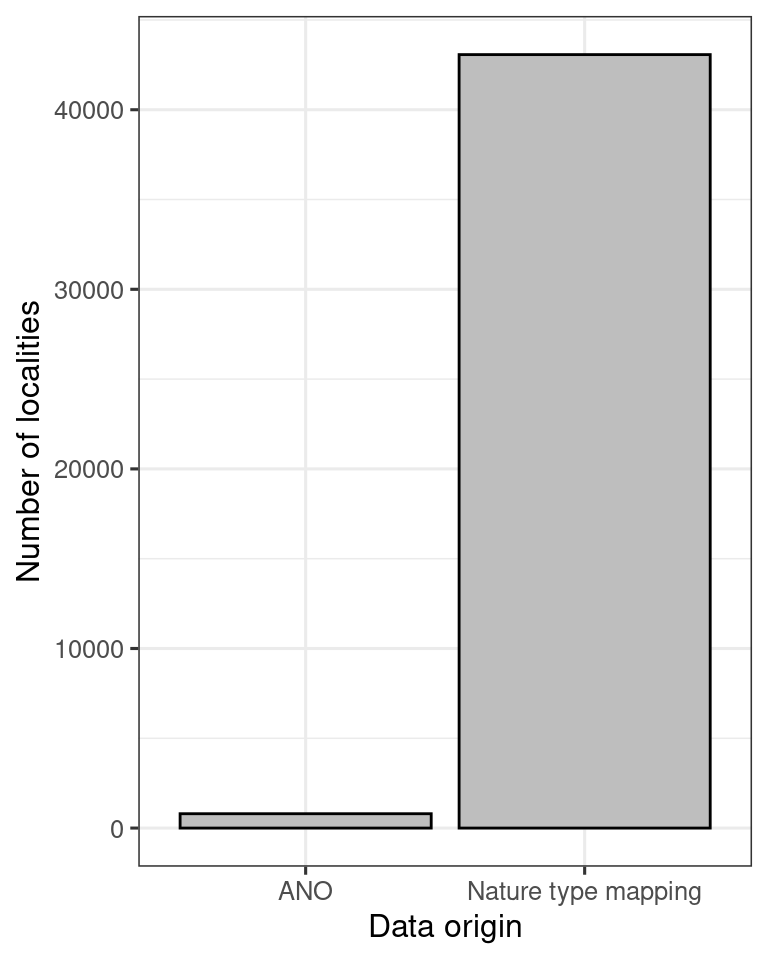
Figure 5.8: Barplot showing the contribution (number of localities) of different data sets to the alien species indicator.
So the ANO data is not very important here, but it can become more important in the future, so good to have them included in the workflow.
5.8.1.5 Outline of Norway and regions
These layers are used to crop out marine areas, and to define accounting areas, respectively.
outline <- sf::read_sf("data/outlineOfNorway_EPSG25833.shp")
regions <- sf::read_sf("data/regions.shp", options = "ENCODING=UTF8")
unique(regions$region)
#> [1] "Nord-Norge" "Midt-Norge" "Østlandet" "Vestlandet"
#> [5] "Sørlandet"Municipalities
path1 <- ifelse(dir == "C:",
"R:/",
"/data/R/")
path <- paste0(path1, "GeoSpatialData/AdministrativeUnits/Norway_AdministrativeUnits/Original/Norway_Municipalities/Basisdata_0000_Norge_25833_Kommuner_FGDB.gdb")
# find the correct layer
#st_layers(path)
muni <- sf::read_sf(path, options = "ENCODING=UTF8", layer = "kommune")There are some multi-surfaces in here that I will convert to multi-polygons before plotting.
# function to make sure that mutipolygons are returned
ensure_multipolygons <- function(X) {
tmp1 <- tempfile(fileext = ".gpkg")
tmp2 <- tempfile(fileext = ".gpkg")
st_write(X, tmp1)
gdalUtilities::ogr2ogr(tmp1, tmp2, f = "GPKG", nlt = "MULTIPOLYGON")
Y <- st_read(tmp2)
st_sf(st_drop_geometry(X), geom = st_geometry(Y))
}
muni <- ensure_multipolygons(muni)
#> Writing layer `file34a3261c663332' to data source
#> `/tmp/RtmpkT1dSD/file34a3261c663332.gpkg' using driver `GPKG'
#> Writing 363 features with 13 fields and geometry type Unknown (any).
#> Reading layer `file34a3261c663332' from data source
#> `/tmp/RtmpkT1dSD/file34a32673f6fef.gpkg'
#> using driver `GPKG'
#> Simple feature collection with 363 features and 13 fields
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: -99551.21 ymin: 6426048 xmax: 1121941 ymax: 7962744
#> Projected CRS: ETRS89 / UTM zone 33N
tm_shape(muni)+
tm_polygons(col="kommunenummer")+
tm_layout(legend.outside = T)
Figure 5.9: Municipalities in Norway.
5.8.2 Scaled indicator values
I can scale the indicator for each polygon, or I can chose to aggregate them first. If the scaled value is representative and precise at the polygon level, then I could scale at that level. I think they are.
However, the combined surveyed area is a very small fraction of the total area of Norway, so that only producing indicator values for the mapped areas leaves the indicator without much value for regional assessments. But we cannot simply do an area weighting of the polygons in each region. This is because we expect considerable sampling bias and we can’t assume that the polygons are representative far outside of the mapped area. But perhaps we can assume them to be representative inside homogeneous ecological areas, or Homogeneous Impact Areas (HIAs). That’s where the infrastructure index comes in. Here’s the plan:
normalise the indicators at the polygon level.
take a simplified infrastructure index (vector data) and intersect this with municipality borders to produce a map of homogeneous impact areas (HIAs).
extract the corresponding indicator values that intersect with a given HIA, and extrapolate the area weighted mean of those values to the entire HIA. Errors are calculated from bootstrapping.
Take the new area weighted indicator values for the HIAs, rasterize it, and mask these with ecosystem occurrences. The errors are the same as for the HIAs.
calculate an indicator value for a region (accounting area) by doing a weighted average based on the relative area of ecosystem occurrences. Errors should be carried somehow, perhaps via weighted resampling.
5.8.2.1 Scaled variable
I will use the same reference levels/values for all of Norway:
low <- 1
high <- 7
threshold <- 3
eaTools::ea_normalise(data = alien_data,
vector = "var_7FA",
upper_reference_level = high,
lower_reference_level = low,
break_point = threshold,
plot=T,
reverse = T
)
#> Warning: Removed 6 rows containing missing values
#> (`geom_point()`).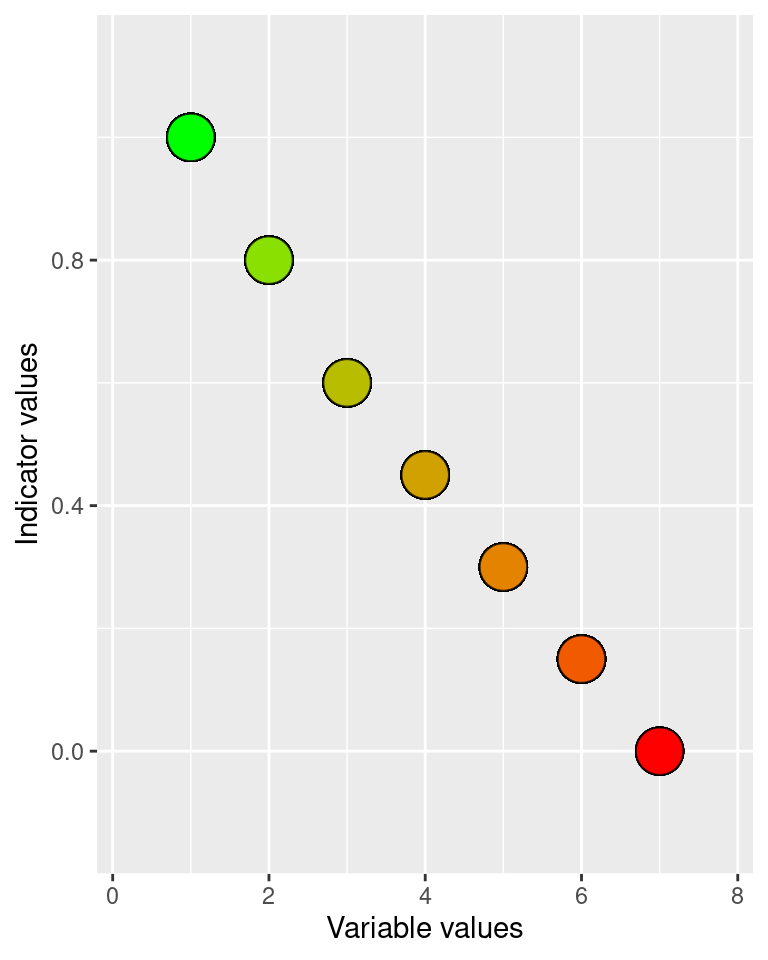
Figure 5.10: Performing a linear break-point type normalisation of the alien species variable.
There is no point yet making this a time series, and I will assign all the indicator values to the average year of the data.
mean(alien_data$kartleggingsår)
#> [1] 2020.12Assigning the indicator to year 2020.
alien_data$i_2020 <- eaTools::ea_normalise(data = alien_data,
vector = "var_7FA",
upper_reference_level = high,
lower_reference_level = low,
break_point = threshold,
reverse = T
)5.8.3 Homogeneous impact areas
I want to use the Homogeneous Impact Areas (HIA) to define smaller regions into which I can extrapolate the indicator values. This data is generated by discretizing the Norwegian Infrastructure Index. I refer to the ordinal values of the four HIA classes as their Human Impact Factor (HIF). This is just to keep the approach separate from the Norwegian Infrastructure Index.
I want to check that HIF is in fact a good predictor for alien species.
I also want to split these four HIA classes based on municipality. For a related indicator I used combinations of HIA and region, but for alien species I think that there is too much variation also inside each region (esp north-south) so that we need a finer division of strata. To do this I need the two layers to have the same CRS.
st_crs(HIA) == st_crs(muni)
#> [1] TRUEThen we get the intersections (unique combinations)
HIA_muni <- eaTools::ea_homogeneous_area(HIA,
muni,
keep1 = "infrastructureIndex",
keep2 = "kommunenummer")
saveRDS(HIA_muni, "P:/41201785_okologisk_tilstand_2022_2023/data/cache/HIA_muni.rds")Create a new column by crossing municipality number and HIF
HIA_muni <- HIA_muni %>%
mutate(muni_HIF = paste("ID", kommunenummer, infrastructureIndex, sep="_"))Here is a view of the data zooming in on Trondheim
myBB <- st_bbox(c(xmin=260520.12, xmax = 278587.56,
ymin = 7032142.5, ymax = 7045245.27),
crs = st_crs(HIA_muni))Cropping the raster to the bbox
HIA_trd <- sf::st_crop(HIA_muni, myBB)
#> Warning: attribute variables are assumed to be spatially
#> constant throughout all geometriesGet map of major roads, for context
hw_utm <- readRDS("data/cache/highways_trondheim.rds")
(HIA_trd <- tm_shape(HIA_trd)+
tm_polygons(col = "infrastructureIndex",
title="Infrastructure index\n(modified 4-step scale)",
palette = "-viridis",
style="cat")+
tm_layout(legend.outside = T)+
tm_shape(hw_utm)+
tm_lines(col="red")+
tm_shape(outline)+
tm_borders(col = "black", lwd=2))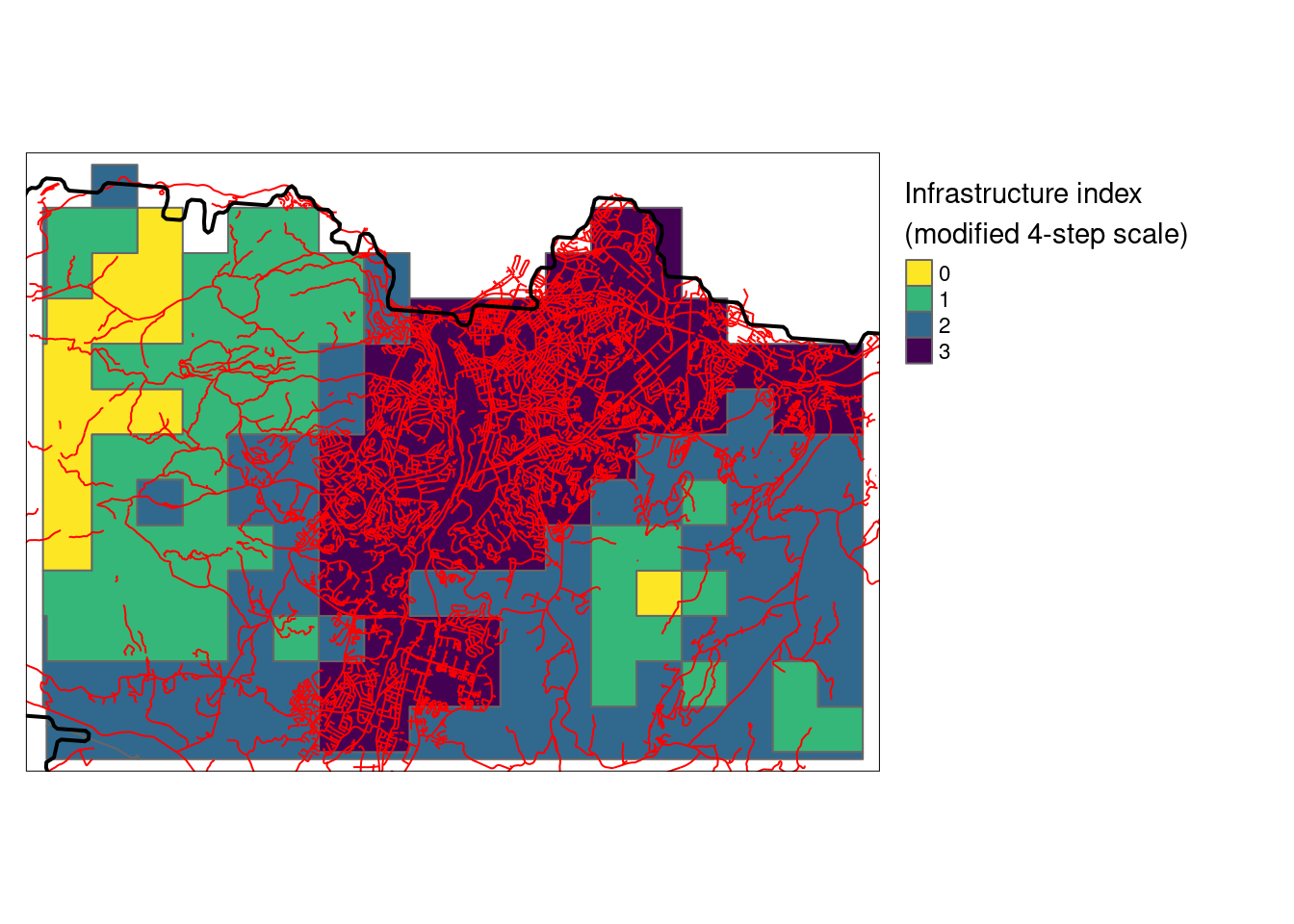
Figure 3.16: A closer look at the HIA designation over Trondheim
See Fig. 3.24 for a closer look at the distribution of HIA classes across Norway.
5.8.3.1 Validate
I now have 1350 HIAs (for each main ecosystem) that I will, given there is data, extrapolate indicator values over. But first I want to validate the assumption that the HIF explains a considerable portion of the variation in the indicator values.
I will subset the alien_data into the three ecosystems.
#make geometries valid
alien_data <- st_make_valid(alien_data)
#subset
wetlands <- alien_data[alien_data$hovedøkosystem == "våtmark",]
seminat <- alien_data[alien_data$hovedøkosystem == "semi-naturligMark",]
natOpen <- alien_data[alien_data$hovedøkosystem == "naturligÅpneOmråderUnderSkoggrensa",]Creating some summary statistics.
wetland_stats <- ea_spread(indicator_data = wetlands,
indicator = i_2020,
regions = HIA_muni,
groups = muni_HIF,
summarise = TRUE)
seminat_stats <- ea_spread(indicator_data = seminat,
indicator = i_2020,
regions = HIA_muni,
groups = muni_HIF,
summarise = TRUE)
natOpen_stats <- ea_spread(indicator_data = natOpen,
indicator = i_2020,
regions = HIA_muni,
groups = muni_HIF,
summarise = TRUE)
wetland_stats <- wetland_stats %>%
add_column(eco = "wetland")
seminat_stats <- seminat_stats %>%
add_column(eco = "semi-natural")
natOpen_stats <- natOpen_stats %>%
add_column(eco = "Naturally-open")
all_stats <- rbind(wetland_stats,
seminat_stats,
natOpen_stats)
all_stats <- all_stats %>%
separate(muni_HIF,
into = c("tempLink", "municipalityNumber", "HIF"),
sep = "_")
#saveRDS(all_stats, "/data/P-Prosjekter2/41201785_okologisk_tilstand_2022_2023/data/cache/all_stats_alienSpecies.rds")
saveRDS(all_stats, "P:/41201785_okologisk_tilstand_2022_2023/data/cache/all_stats_alienSpecies.rds")We have data from 277 out of 363 municipalities. This figure shows how many municipalities we have at least one data point for, specific for each human impact factor level:
all_stats %>%
group_by(HIF, eco) %>%
summarise(n = n()) %>%
ggplot()+
geom_bar(aes(x = HIF, y = n), stat ="identity")+
theme_bw()+
ylab("Number of municipalities")+
facet_wrap(.~eco)
#> `summarise()` has grouped output by 'HIF'. You can override
#> using the `.groups` argument.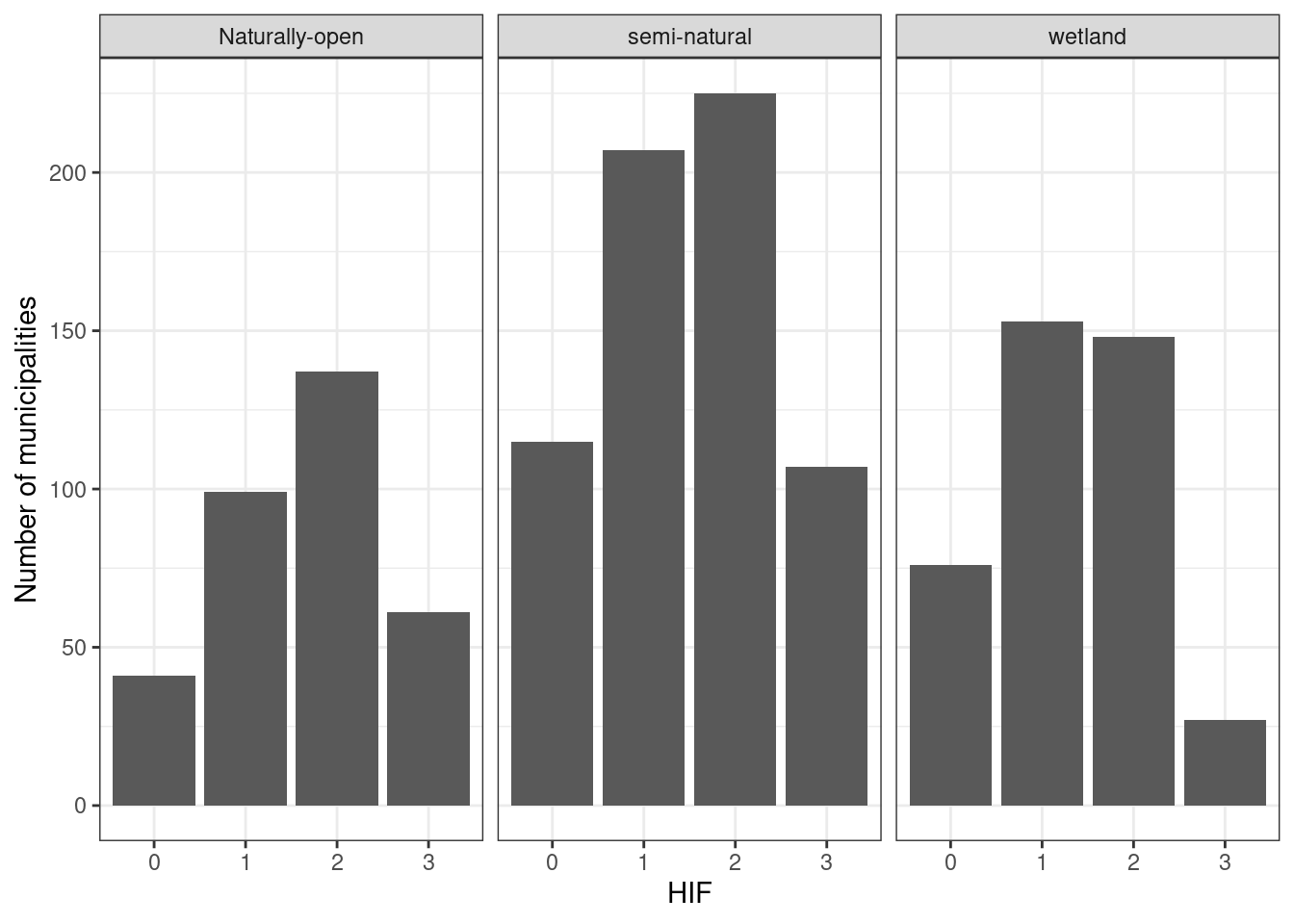
Figure 5.11: Number of municipalities we have at least one data point for, specific for each human impact factor level.
If we say that we need 20 data points for each HIA and municipality combination in order to extrapolate to the entire HIA for that municipality, we get much less to work with:
all_stats %>%
filter(n>20) %>%
group_by(HIF, eco) %>%
summarise(n = n()) %>%
ggplot()+
geom_bar(aes(x = HIF, y = n), stat ="identity")+
theme_bw()+
ylab("Number of municipalities")+
facet_wrap(.~eco)
#> `summarise()` has grouped output by 'HIF'. You can override
#> using the `.groups` argument.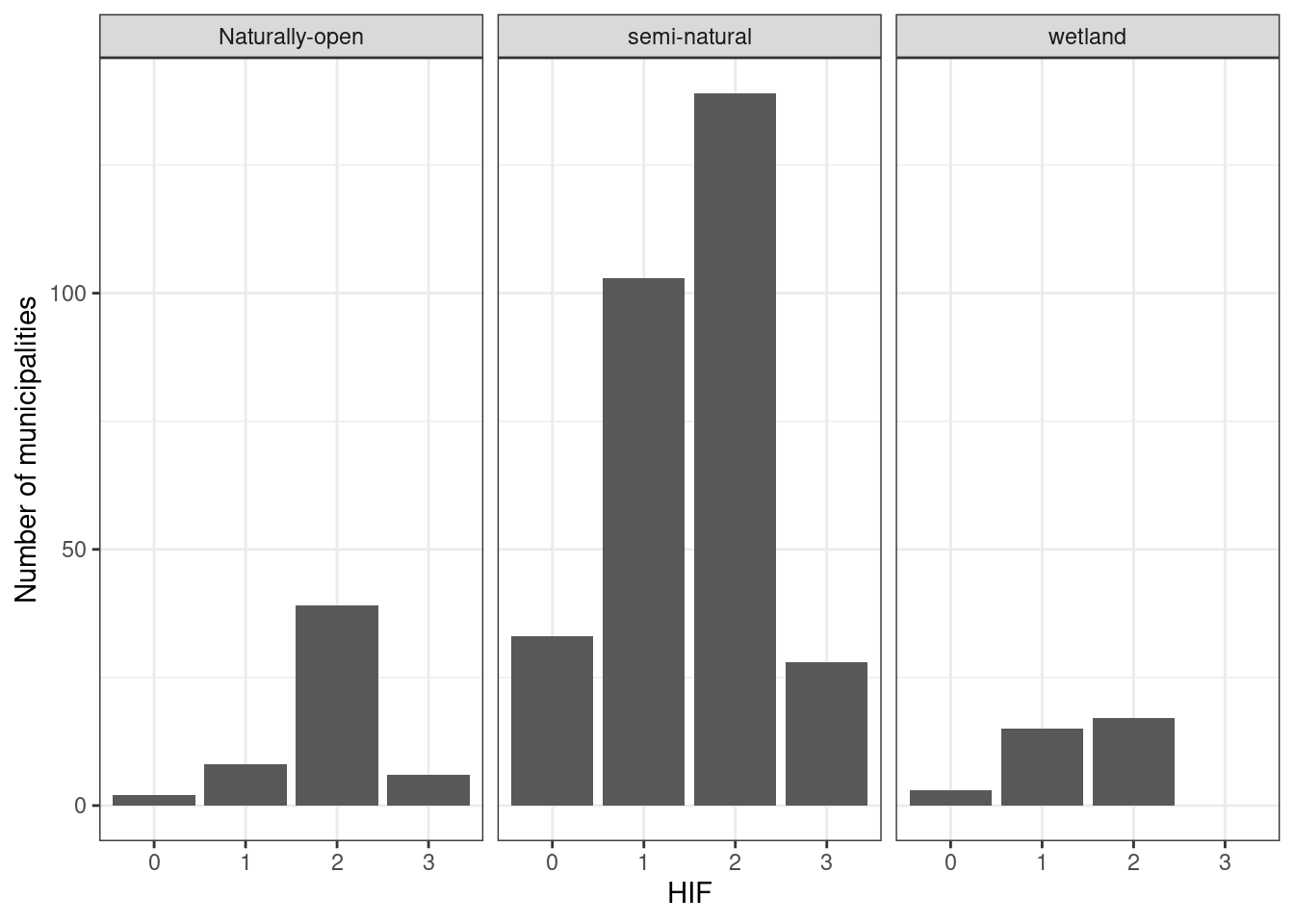
Figure 5.12: Number of municipalities we have at least 20 data points for, specific for each human impact factor level.
all_stats %>%
filter(n > 20) %>%
ggplot(aes(x = HIF, y = w_mean))+
geom_point(size=2, position = position_dodge2(.1))+
geom_violin(alpha=0)+
theme_bw()+
labs(x = "Human impact factor",
y = "Indicator value (area weighted means)")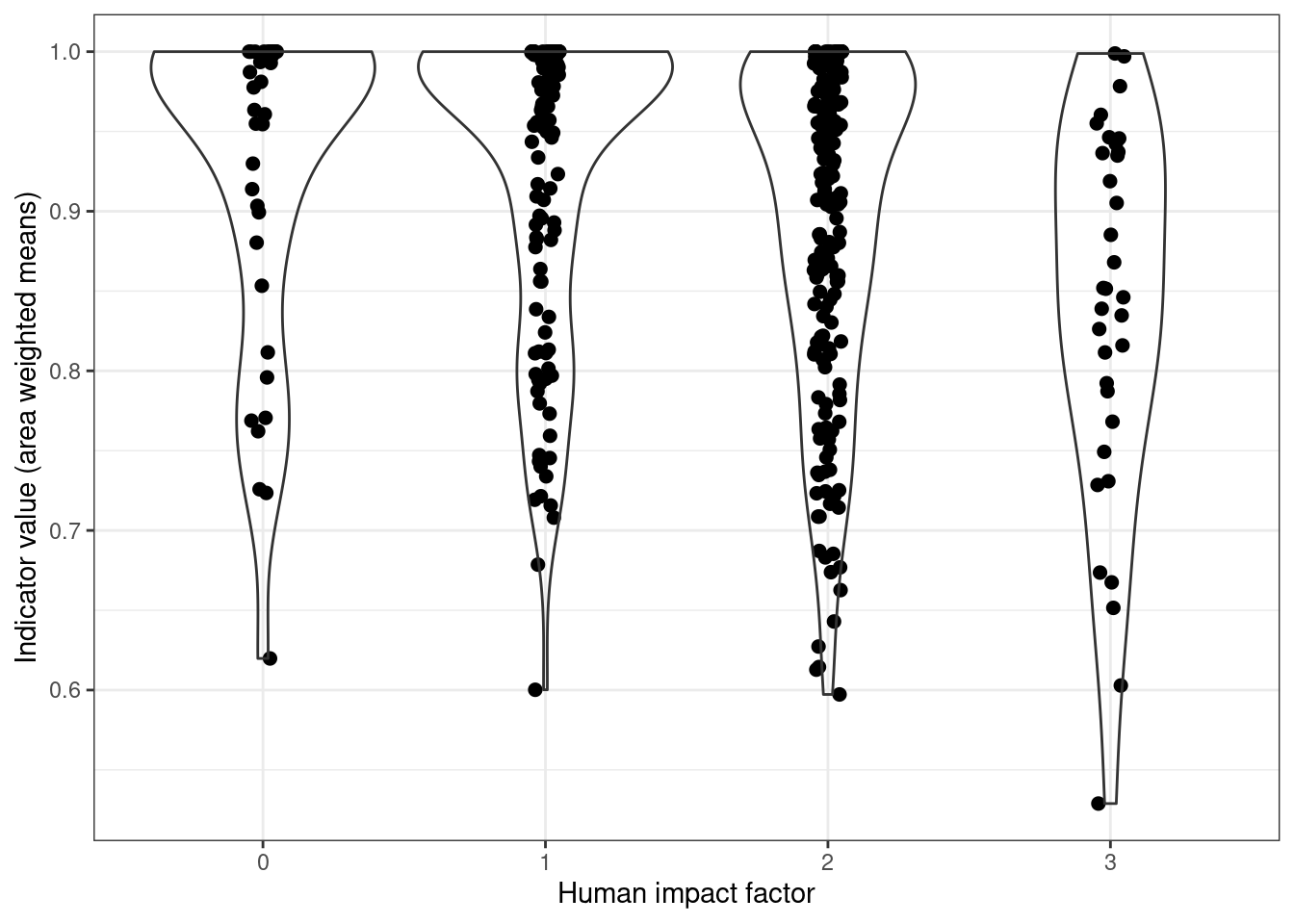
Figure 5.13: Indicator-pressure relationship across all ecosystems.
There is a trend here, but not very strong perhaps.
Here is a similar figure, looking at the relative frequency of indicator level of polygons and within each HIA.
corrCheck <- st_intersection(alien_data, HIA)
saveRDS(corrCheck, paste0(pData, "cache/corrCheck_alienSpecies.rds")
ggplot(corrCheck, aes(x = factor(infrastructureIndex), fill = factor(round(i_2020,2))))+
geom_bar(position="fill")+
theme_bw(base_size = 12)+
guides(fill = guide_legend("Alien species indicator"))+
ylab("Fraction of data points")+
xlab("HIF")+
scale_fill_brewer(palette = "RdYlGn")+
facet_wrap(.~hovedøkosystem)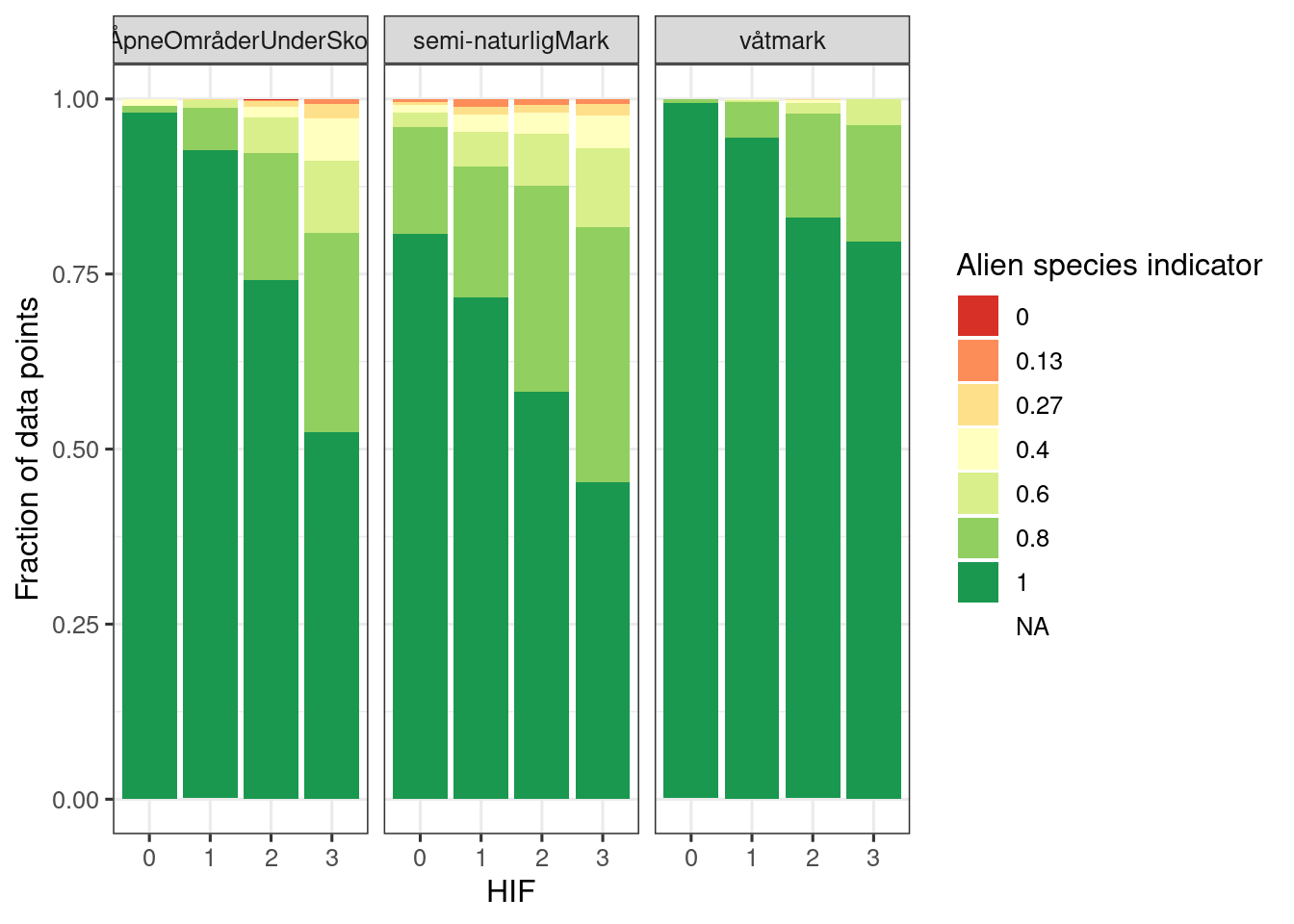
Figure 5.14: Relative frequency plot showing the distribution of polygons with different indicator values.
The figure above I think supports the indicator-pressure relationship and justifies using the HIA x municipality intersections as local reference areas.
Let us look at the effect of sample size on the indicator uncertainty.
all_stats %>%
filter(n > 5) %>%
ggplot(aes(x = n, y = sd))+
geom_point(size=2, position = position_dodge2(.1))+
theme_bw()+
facet_wrap(.~eco, scales="free")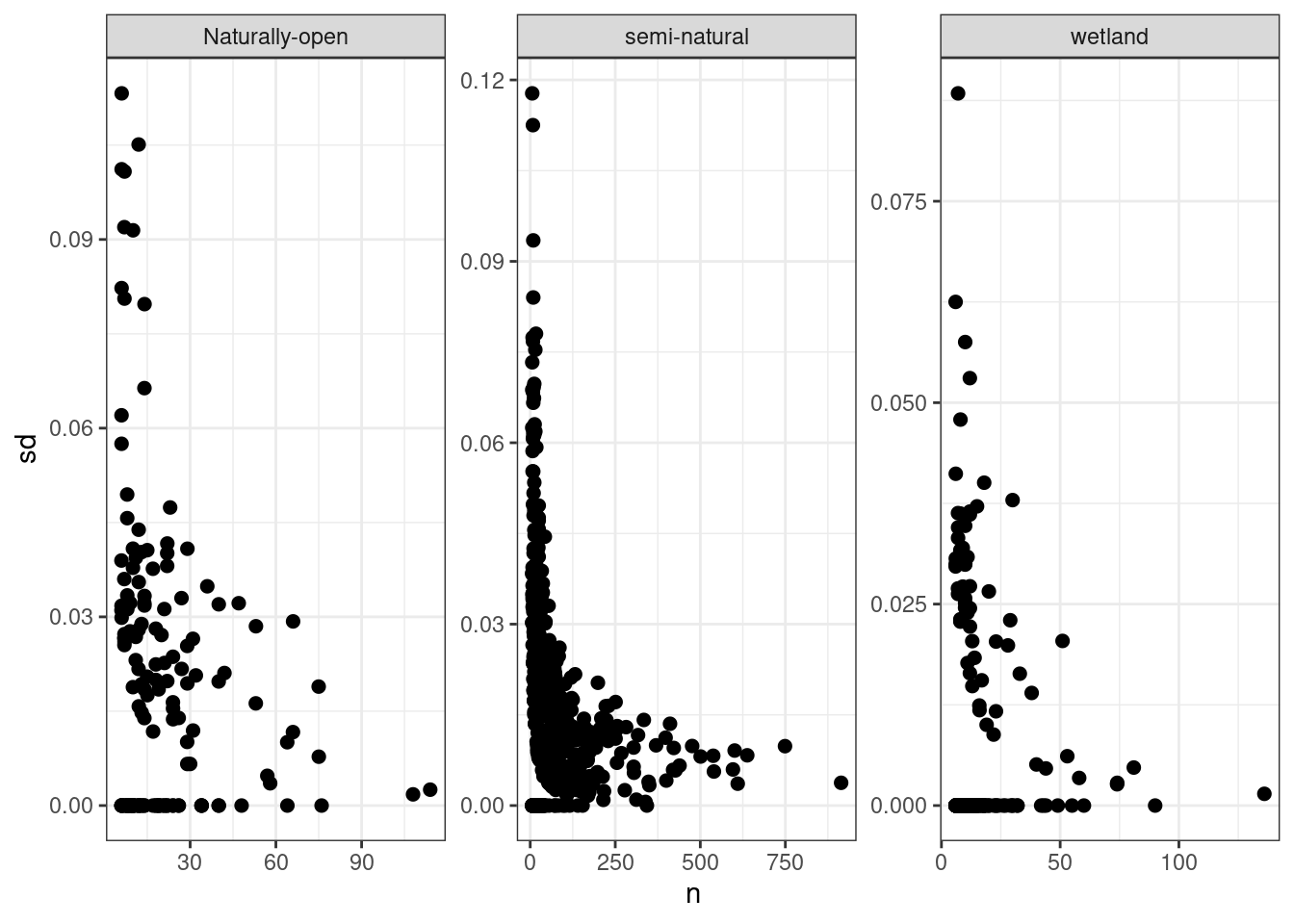
Figure 5.15: Sample size against indicator uncertainty.
This shows that the uncertainty is really inflated with sample sizes less than about 50-100.
DT::datatable(all_stats) %>%
formatRound(columns=3:8, digits=2)Figure 5.16: Summary statistics for the alien species indicator.
5.8.4 Aggregate and spread (extrapolate)
I now want to find the mean indicator value for each HIA (i.e. to aggregate) and to spread these out spatially to the entire HIA (i.e. to extrapolate).
I want to add a threshold so that we don’t end up over extrapolating based on too few data points. I will use 20 data points as a minimum.
wetland_alien_extr <- ea_spread(indicator_data = wetlands,
indicator = i_2020,
regions = HIA_muni,
groups = muni_HIF,
threshold = 20)
seminat_alien_extr <- ea_spread(indicator_data = seminat,
indicator = i_2020,
regions = HIA_muni,
groups = muni_HIF,
threshold = 20)
natOpen_alien_extr <- ea_spread(indicator_data = natOpen,
indicator = i_2020,
regions = HIA_muni,
groups = muni_HIF,
threshold = 20)It’s easier to see what’s happening if we zoom in a bit. I will look more closely at three example municipalities:
Trondheim (municipality nr 5001), Nordre Follo (3020) and Målselv (5418).
wetland_alien_extr <- wetland_alien_extr %>%
separate(ID,
into = c("ID", "municipalityNumber", "HIF"),
sep = "_") %>%
add_column(eco = "wetlands")
seminat_alien_extr <- seminat_alien_extr %>%
separate(ID,
into = c("ID", "municipalityNumber", "HIF"),
sep = "_") %>%
add_column(eco = "semi_natural")
natOpen_alien_extr <- natOpen_alien_extr %>%
separate(ID,
into = c("ID", "municipalityNumber", "HIF"),
sep = "_") %>%
add_column(eco = "naturally_open")
alien_extr <- rbind(
wetland_alien_extr,
seminat_alien_extr,
natOpen_alien_extr
)
myCol <- "RdYlGn"
tmap_arrange(
tm_shape(alien_extr_trd_nf)+
tm_polygons(col = "w_mean",
title="Alien species indicator",
palette = myCol,
style="fixed",
breaks = seq(0,1,.1))+
tm_layout(legend.outside = T)+
tm_facets(by=c("eco", "municipalityNumber"))
,
tm_shape(alien_extr_trd_nf)+
tm_polygons(col = "HIF",
title="Human impact factor",
palette = "-viridis",
style="cont",
breaks = c(0,1))+
tm_layout(legend.outside = T)+
tm_facets(by=c("municipalityNumber"))
,
ncol=1,
heights = c(1,0.3))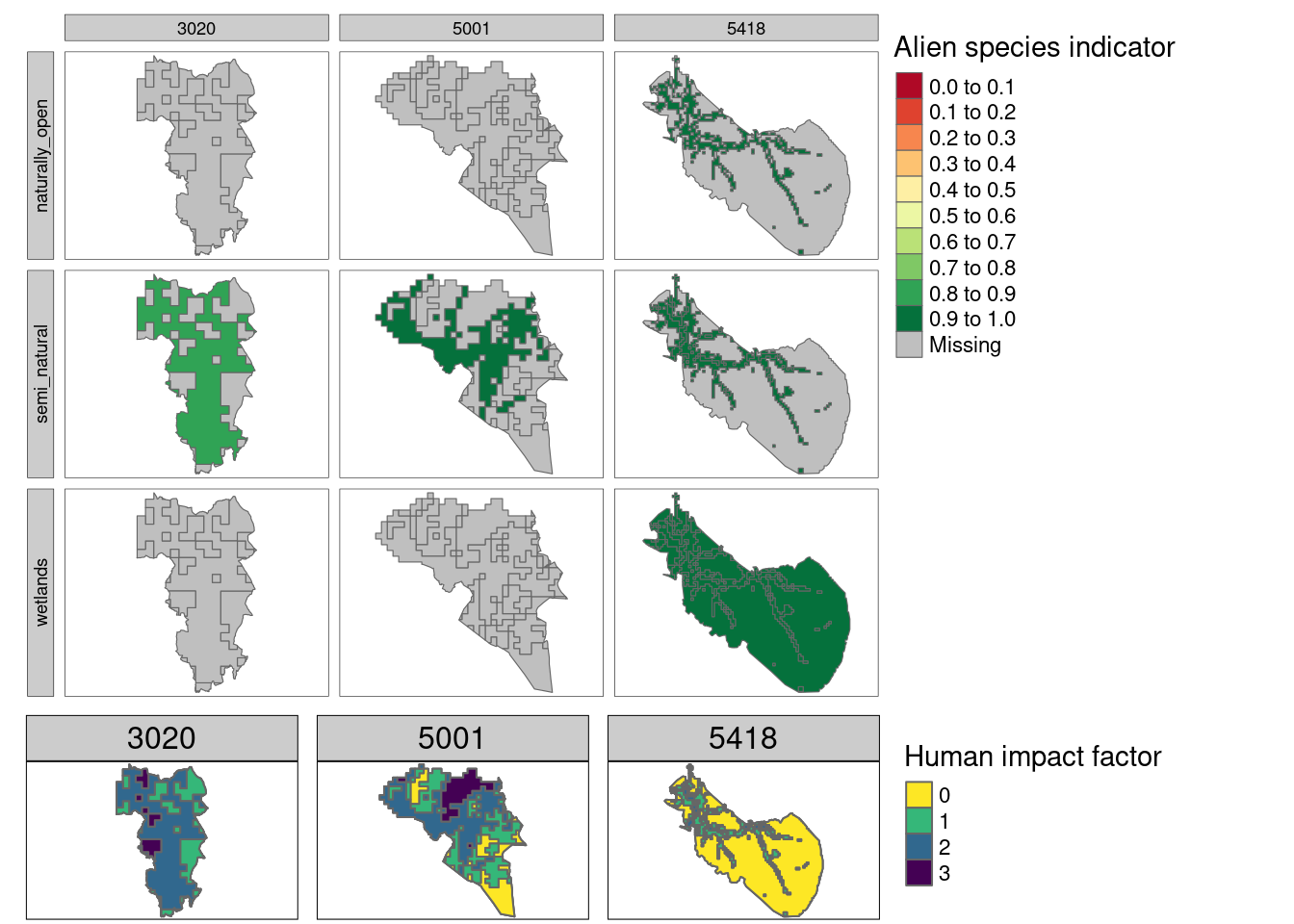
Figure 5.17: Alien species indicator extrapolated over Nordre Follo (3020), Trondheim (5001) and Målselv (5418). Note that the maps are not masked by ecosystem type, so the three ecosystem specific indicators are overlaping. The bottom row shows the location of the four human impact sones.
Figure 5.17 again indicates that this indicator will have a lot of missing data (see also here). For Nordre Follo and Trondheim for example, we do not have any indicator values tied to naturally open or wetland ecosystems, and for semi natural ecosystems we only have data for HIF class 2. This is, however, still a lot better than discarding the entire data set due to issues related to area representativity. The amount of missing data in the indicator maps is closely tied to the chosen threshold value for how many data points we must have in order to calculate an (area weighted) mean indicator value. We have used 20 as the threshold here. For Målselv (far right column), we ended up having enough data for wetlands in HIF class 0, and since most of the municipality is in this HIF class we get a lot of indicator coverage.
The following table contains the data values underlying Figure 5.17, including HIAs with <20 data points.
all_stats %>%
filter(municipalityNumber %in% c("5001", "3020", "5418")) %>%
arrange(municipalityNumber, eco, HIF) %>%
DT::datatable()%>%
formatRound(columns=3:8, digits=2)Figure 5.18: Summary statistics for three example municipalities.
Note that we can also show the uncertainties on maps:
tm_shape(alien_extr_trd_nf[alien_extr_trd_nf$eco=="semi_natural",])+
tm_polygons(col = "sd",
title="SD(alien\nspecies indicator)",
palette = "-viridis"
)+
tm_layout(legend.outside = T)+
tm_facets(by="municipalityNumber")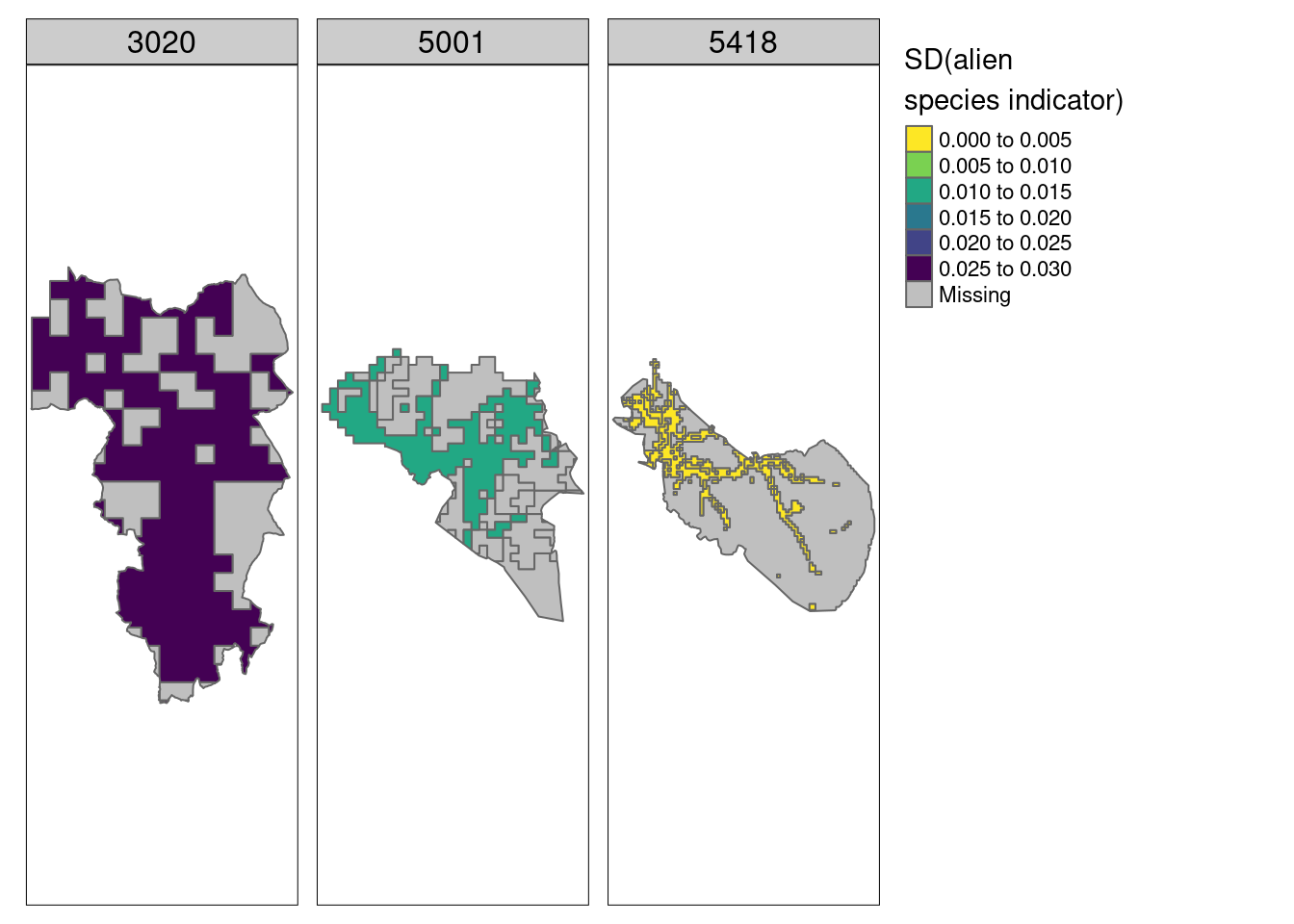
Figure 5.19: Map showing the uncertainties (spatial variation) around the indicator values for alien species in three example municipalities for Semi-natural ecosystems.
5.8.5 Exploring the indicator values
Most HIAs have good condition:
alien_extr %>%
filter(!is.na(w_mean)) %>%
ggplot()+
geom_histogram(aes(x = w_mean))+
theme_bw()+
labs(x = "Area weighted indicator value",
y = "Number of HIAs with >20 data points")
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.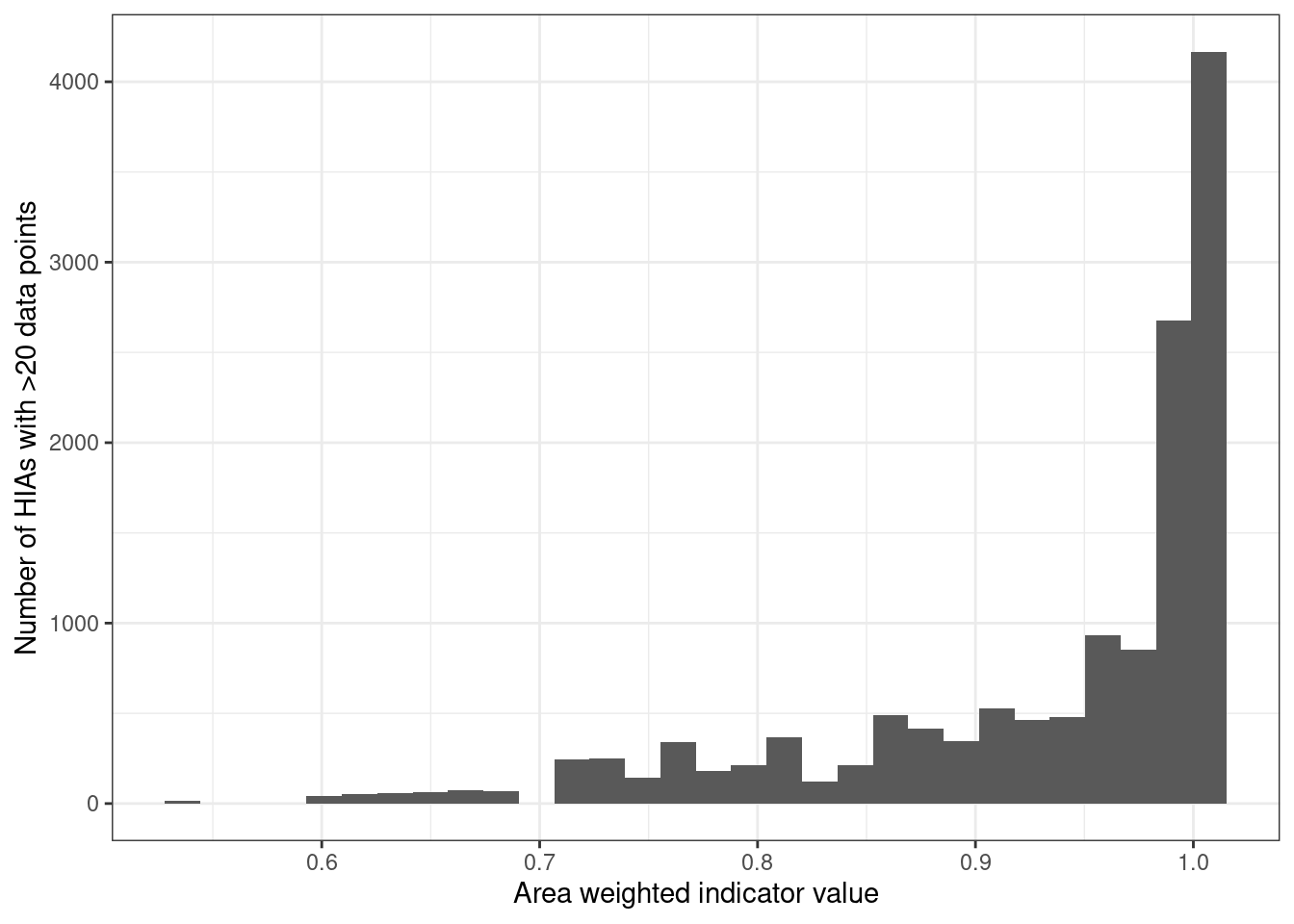
Figure 5.20: Number of HIAs with >20 data points (sum of all three ecosystems)
5.8.5.1 Data coverage
Let’s see how big proportion of Norway we ended up having data for. Ideally I would do this after masking the indicator maps with ecosystem delineations, but I can also get a good feel for the data coverage like this as well.
The area of Norway is
(total_area <- st_area(outline))
#> 325694265348 [m^2]And here is the total and relative area of the indicator maps
alien_extr %>%
filter(!is.na(w_mean)) %>%
mutate(m2 = st_area(.)) %>%
group_by(eco) %>%
summarise(sum_area = sum(m2)) %>%
add_column(total_area = total_area) %>%
mutate(relative_area = units::drop_units(sum_area/total_area)) %>%
ggplot()+
geom_bar(aes(x = eco, y = relative_area),
stat = "identity")+
labs(x = "Ecosystem", y = "Relative indicator data coverage")+
theme_bw()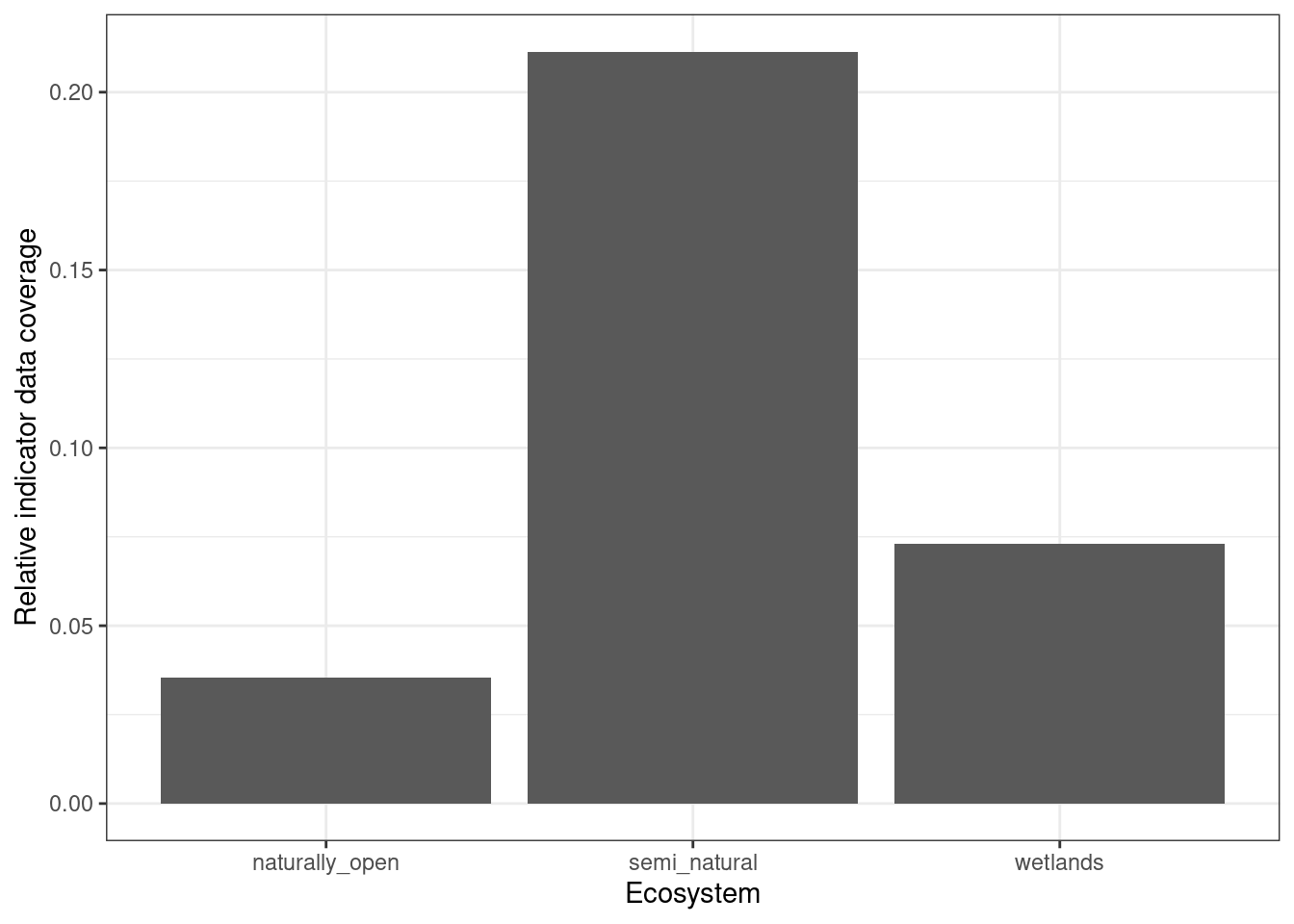
Figure 5.21: Relative area cover of the indicator maps for the alien species indicator (i.e. value 1 means that all HIAs had > 20 data points, and 0.2 means 20% of them did). If assuming the ecosystems are equally common where they are mapped and where they are not, this measure of data coverage is representative of the real indicator coverage after masking the maps with ecosystem delineations.
Figure 5.21 shows us that this indicator will provide indicator values for about 20% of the semi-natural ecosystem, and considerably less for the other two ecosystems. The data coverage is very sensitive to the threshold for minimum data points, set to >20 in this case. Also, with more nature type data accumulating over time, the data coverage will increase. Therefore I think this indicator is worthwhile, and that this is considerably better than the alternative to discard the entire data set.
5.8.5.2 Effect of latitude
Alien species can be expected to decrease towards the north. Let us see if there is an effect of latitude.
Extracting x and y coordinates
temp <- alien_extr %>%
filter(!is.na(w_mean)) %>%
st_centroid() %>%
st_coordinates()
temp2 <- alien_extr %>%
filter(!is.na(w_mean)) %>%
cbind(temp)
temp2 %>%
ggplot(aes(x = X, y = w_mean))+
geom_point()+
theme_bw()+
geom_smooth(linewidth=2,
method="loess",
span=0.75)+
labs(x = "Latitude (UTM with offset)",
y = "Alien species indicator value\n(area weighted)")+
facet_wrap(~eco)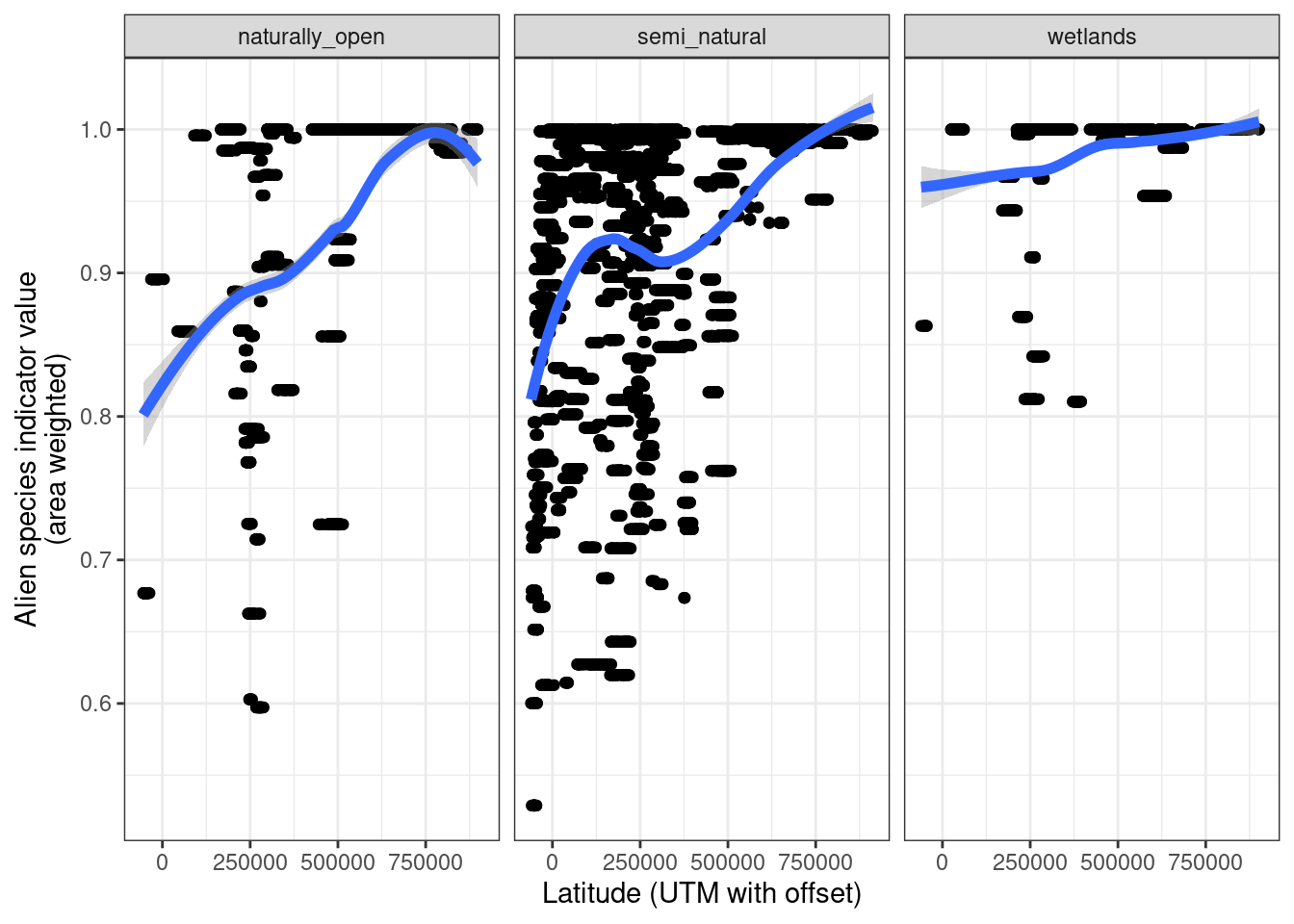
Figure 5.22: Effect of latitude on the alien species indicator values. The blue line is a loess smoother (span=0.75).
There is a quite clear association here between latitude and the on-site effect of alien species.
5.9 Next steps
The next steps now are to
Prepare ecosystem delineation maps in EPSG:25833 and perfectly aligned to a master grid
Rasterize the extrapolated indicator map, using the ET map as a template
and mask it using the perfectly aligned ET map.
Then, look at Median Summer Temperature for how to aggregate spatially to accounting areas (regions)
This workflow should be synchronized with the slitasje indicator. I will attempt a little proof of concept below.
5.10 Masking with an ecosystem delineation - example
Let’s try steps 2 and 3 on a reduced data set. I’ll work with wetlands in Gran municipality.
gran <- wetland_alien_extr %>%
filter(municipalityNumber == "3446")
tm_shape(gran)+
tm_polygons(col = "w_mean",
title="Alien species indicator - wetlands",
palette = myCol,
style="fixed",
breaks = seq(0,1,.1))+
tm_layout(legend.outside = T,
title = "Gran municipality")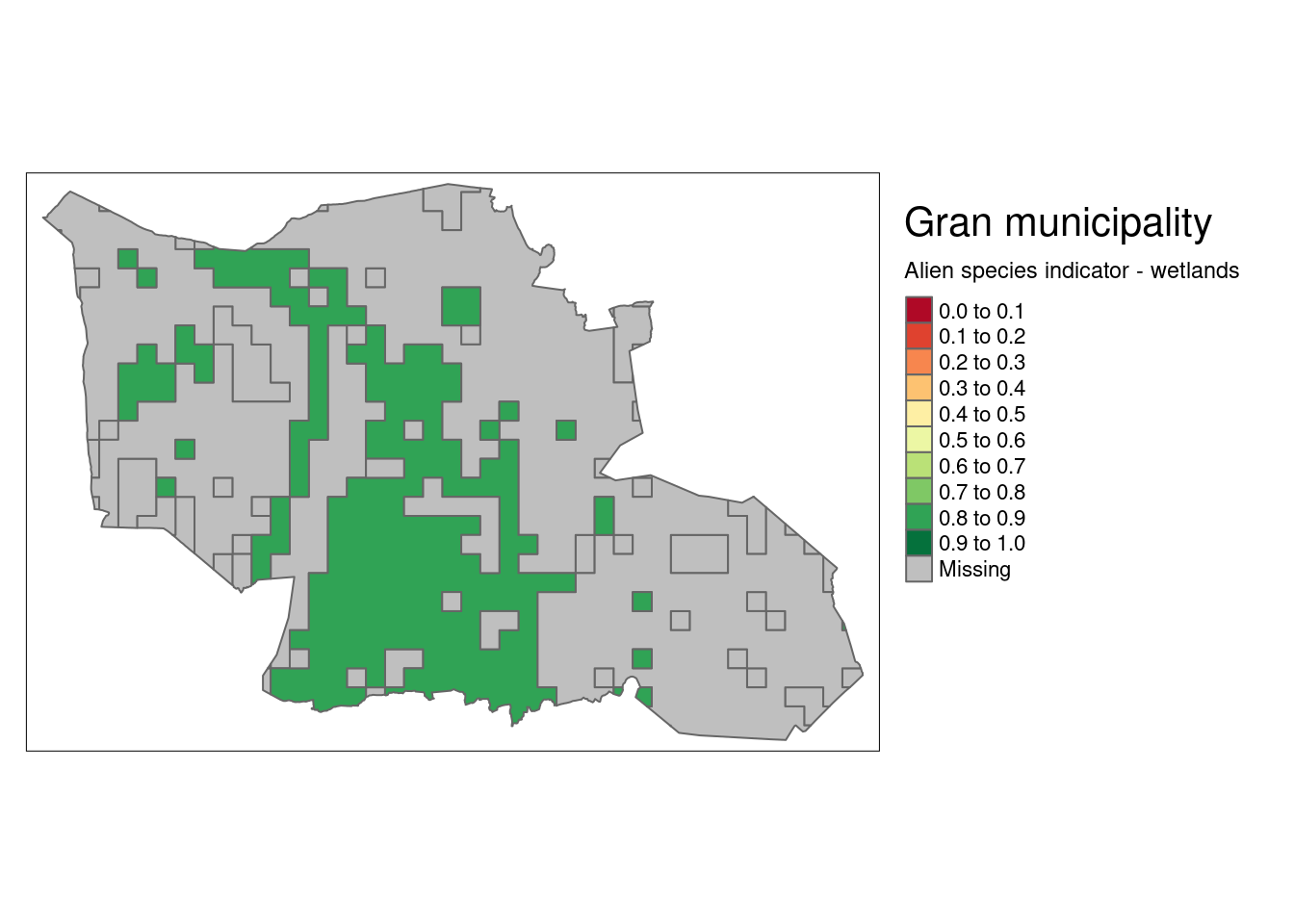
Figure 3.23: Alien species indicator over wetlands in Gran municipality.
Then I can import and crop the ecosystem delineation map (EDM).
file <- "P:/41201785_okologisk_tilstand_2022_2023/data/Myrmodell/myrmodell90pros.tif"
EDM <- stars::read_stars(file, proxy=F)The EDM is in UTM32 when we actually want to have it in UTM33. But transforming it takes too long, so I will transform the indicator map instead.
gran <- st_transform(gran, st_crs(EDM))
ggplot()+
geom_stars(data = st_downsample(mire_gran, 10))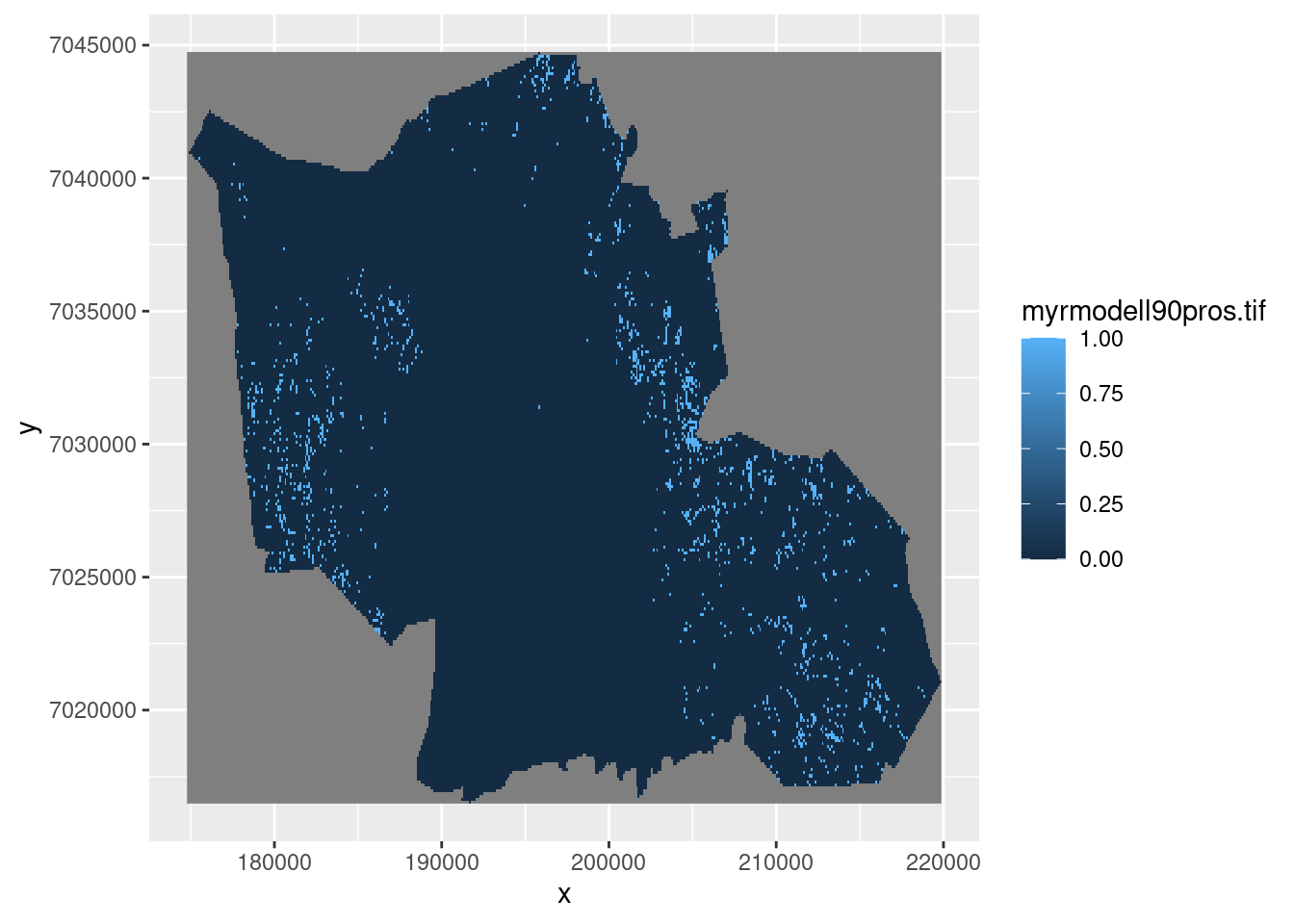
Figure 5.23: Wetlands in Gran municipality
Then I rasterize the indicator map to match the EDM. This takes a while, even for just one municipality. I’m not sure this would work for the entire country.
gran_rast <- st_rasterize(gran, template = mire_gran)
saveRDS(gran_rast, paste0(pData, "cache/gran_rast.rds"))
gran_outline <- muni %>%
filter(kommunenummer == "3446")
tm_shape(st_downsample(gran_rast, 10))+
tm_raster(col="w_mean")+
tm_shape(gran_outline)+
tm_borders(col="red")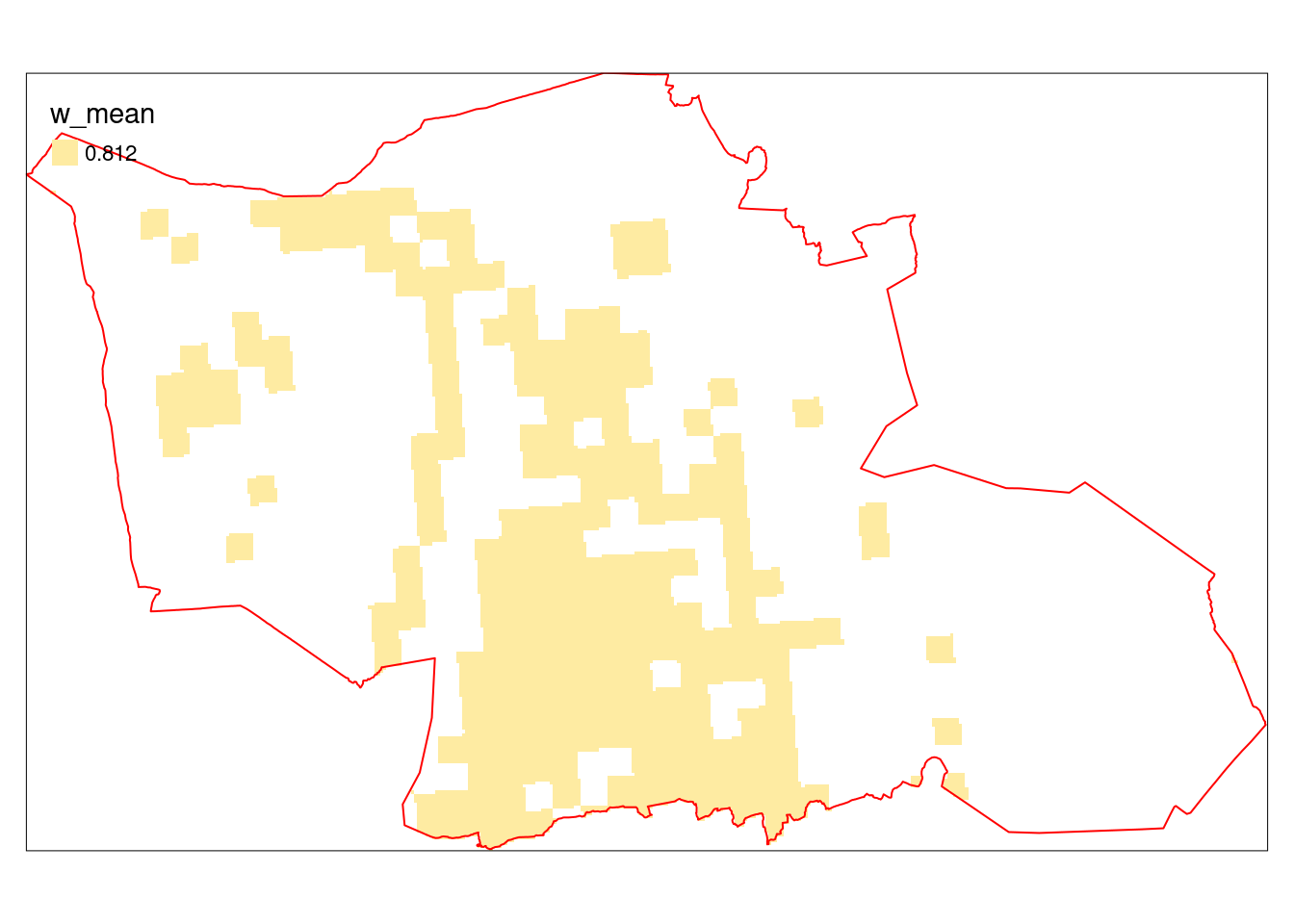
Figure 5.24: Indictor values (alien species, extrapolated and area weighted values) in Gran municipality. Note that the pixelation is very small (10 x 10 m), and that the larger squares are remnants from the HIA map which was 1 x 1 km resolution.
Then I mask to remove areas that are not actually wetlands.
gran_rast_masked <- gran_rast
gran_rast_masked[mire_gran == 0] <- NA
tm_shape(st_downsample(gran_rast_masked, 10))+
tm_raster(col="w_mean",
palette = "red")+
tm_shape(gran_outline)+
tm_borders(col="red")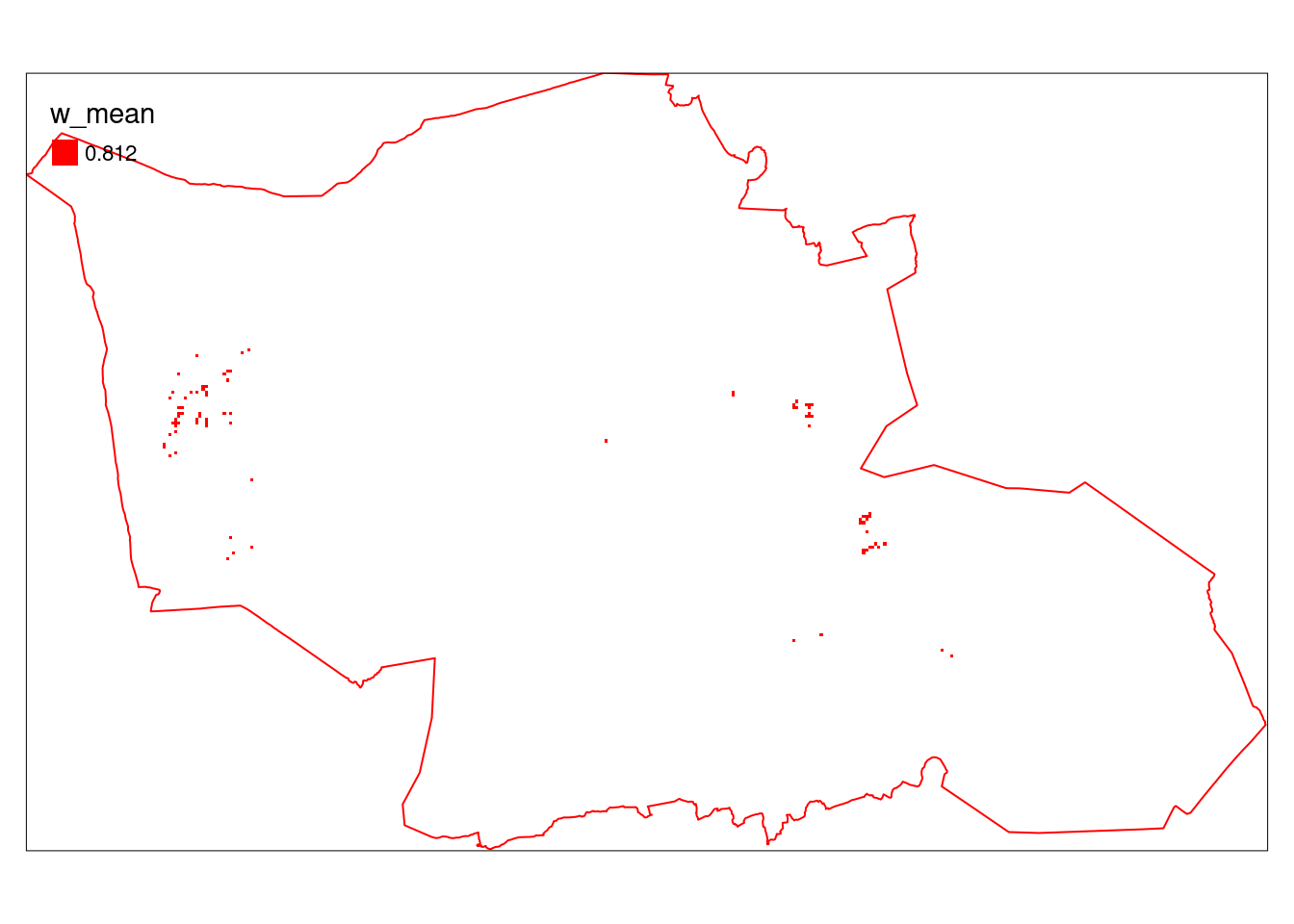
Figure 5.25: Stratified, area weighted indictor values (alien species) in Gran municipality masked by a wetland ecosystem delimination map.
From here it is easy to get zonal statistics using exactextratr. If I have this kind of map for all of Norway I can get the mean value for the regions (defined via a polygon set) and it will of course be area weighted (but no weight given to ecosystem occurences that don’t have indicator values).